LLMOps 入门(二):Arize Phoenix 实战指南——环境搭建、追踪、评估与实验
LLMOps 入门(二):Arize Phoenix 实战指南——环境搭建、追踪、评估与实验
引言
在上一篇《LLMOps 入门(一):概念解析、框架概览与实践启航》中,我们共同探讨了 LLMOps 的核心理念及其对于高效、可靠地开发和运维大型语言模型(LLM)应用的关键作用。通过一个智能客服系统的案例,我们具体感知了 LLMOps 在项目全生命周期中的价值。我们还初步了解了几款主流的开源 LLMOps 框架,并基于易用性、轻量级特性以及对初学者友好等因素,选择了 Arize Phoenix 作为本系列后续深度实践的核心工具。
欢迎来到 LLMOps 入门系列的第二篇文章! 本篇将聚焦于 Arize Phoenix,手把手带领大家完成 Phoenix 的环境搭建,并深入探索其在 LLM 应用开发中的核心功能:从自动化的调用追踪、便捷的 Prompt 与 Dataset 管理,到强大的模型输出评估及实验驱动的优化。我们的目标是,通过本指南,您可以快速上手 Phoenix,并将其应用于您的 LLM 项目中,为后续更精细化的模型调优和运维打下坚实基础。
Phoenix 概览与核心优势
Arize Phoenix 是一个专为 AI 工程师和数据科学家设计的开源库,旨在提供对 LLM 应用的评估和故障排除能力。它能够帮助您理解模型的行为、诊断问题、评估输出质量,并最终提升应用的整体性能和可靠性。
选择 Phoenix 作为本系列的核心工具,主要基于以下考量:
- 轻量级与易用性:Phoenix 的设计注重简洁和快速上手,其本地优先的特性使得开发者无需复杂的云端配置即可开始使用。
- 全面的可观测性:它提供了对 LLM 调用、Prompt、数据集、评估结果和实验过程的全面追踪和可视化。
- 强大的评估框架:内置多种评估指标和工具,支持对模型幻觉、问答正确性等进行量化评估。
- 实验驱动:支持结构化的实验流程,便于比较不同模型、Prompt 或参数的效果。
- 广泛的集成:能够与 OpenAI、LangChain、LlamaIndex 等主流 LLM 开发框架和库良好集成。
接下来,让我们正式踏上 Phoenix 的实践之旅。在本指南的后续部分,我们将首先完成必要的准备工作和环境初始化,确保 Phoenix 顺利运行。随后,我们将逐一深入探讨 Phoenix 的各项核心功能:如何有效地追踪 LLM 调用与会话、如何系统地管理 Prompt 和数据集、如何利用内置工具评估模型输出的质量,以及如何通过结构化的实验来驱动应用的优化。

准备工作
在开始之前,请确保您已经安装了 arize-phoenix 库以及本教程中将用到的其他辅助库。如果尚未安装,可以通过 pip 进行安装。
pip install arize-phoenix openai python-dotenv loguru langchain llama-index pandas nest_asyncio
请在您的开发环境中执行以上命令(如果尚未安装)。同时,确保您拥有必要的 API 密钥(如 OpenAI API Key)并已配置好相应的开发环境。
1. 环境初始化
使用 Phoenix 前,需要进行一些必要的初始化设置。
1.1 启动 Phoenix 应用
首先,我们需要导入 phoenix 库并启动 Phoenix 应用。Phoenix 应用是一个在本地运行的服务,它负责收集、存储和展示您的 LLM 应用的追踪数据。通过启动这个应用,您将能够在一个网页界面上直观地查看和分析这些数据。
import phoenix as px
# 启动 Phoenix 应用
# 这会在您的本地机器上启动一个 Web 服务,通常默认监听 6006 端口
session = px.launch_app()
启动成功后,控制台会显示 Phoenix UI 的访问地址,通常是 http://localhost:6006/。您可以将此地址复制到浏览器中打开,后续的追踪数据都将在这个界面上展示。
1.2 导入必要的库
接下来,我们导入本教程后续步骤中会用到的一些核心 Python 库。
import openai # OpenAI 官方 Python 客户端库
import uuid # 用于生成全局唯一标识符 (UUID)
import pandas as pd # 强大的数据分析和处理库
from loguru import logger # 一个优雅、简洁的日志记录库
from enum import Enum # 用于创建枚举类型,方便管理常量集合
# Phoenix 库的核心组件导入
from phoenix.otel import register # 用于注册 OpenTelemetry instrumentor,实现自动追踪
from phoenix.client.types import PromptVersion # Phoenix 中用于定义 Prompt 版本的特定类型
from phoenix.evals import ( # Phoenix 评估模块
HallucinationEvaluator, # 用于评估模型输出是否包含幻觉
OpenAIModel, # 定义用于评估的 LLM (通常是能力较强的模型)
QAEvaluator, # 用于评估问答任务的正确性
run_evals, # 执行批量评估的函数
llm_generate # 使用 LLM 批量生成数据的函数
)
from phoenix.experiments import run_experiment # Phoenix 实验管理模块
# 从 OpenAI 库导入类型提示,有助于代码编辑和静态分析
from openai.types.chat.completion_create_params import CompletionCreateParamsBase
from openai import OpenAI
import functools
# 在 Jupyter Notebook 或类似异步环境中,nest_asyncio 允许嵌套事件循环,
# 这对于某些异步库(包括 Phoenix 的部分功能)的顺畅运行可能很重要。
import nest_asyncio
nest_asyncio.apply()
1.3 设置环境变量
为了让 Phoenix 能够与您使用的 LLM 服务(例如 OpenAI)以及可能的远程 Phoenix 收集器(如果您使用 Arize Cloud 服务)正确通信,需要配置一些环境变量。一个推荐的做法是将这些敏感信息或配置信息存储在项目根目录下的 .env 文件中,然后使用 python-dotenv 库来加载它们。
主要涉及的环境变量包括:
OPENAI_API_KEY: 您的 OpenAI 服务 API 密钥。OPENAI_BASE_URL: OpenAI API 的基础 URL。如果您使用的是官方 OpenAI 服务,则可以不设置此项或使用默认值。但在使用 Azure OpenAI 或其他代理服务时,需要指定对应的 URL。PHOENIX_API_KEY和PHOENIX_COLLECTOR_ENDPOINT: 这些主要在您希望将数据发送到 Arize Cloud 托管的 Phoenix 服务时使用。对于本教程中主要使用的本地 Phoenix 应用,通常不需要设置它们。OTEL_EXPORTER_OTLP_HEADERS: 在连接到需要认证的 OTLP 收集器(如 Arize Cloud)时,用于传递认证头部信息(例如包含PHOENIX_API_KEY)。
下面的代码演示了如何加载这些环境变量,并包含了一个处理本地与远程收集器切换的逻辑:
import dotenv
import os
# 从 .env 文件加载环境变量到当前会话
dotenv.load_dotenv()
# 示例:如果您计划使用 Arize Cloud,可能会需要如下设置
# phoenix_api_key = os.environ.get('PHOENIX_API_KEY')
# if phoenix_api_key:
# os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"Authorization=Bearer {phoenix_api_key}"
# 对于本地 Phoenix 应用,我们通常希望数据发送到本地启动的服务。
# 如果不小心在环境中设置了 PHOENIX_COLLECTOR_ENDPOINT 指向远程服务,
# 以下代码会将其删除,从而确保数据流向本地。
if 'PHOENIX_COLLECTOR_ENDPOINT' in os.environ:
del os.environ['PHOENIX_COLLECTOR_ENDPOINT']
logger.info("Removed PHOENIX_COLLECTOR_ENDPOINT to use local Phoenix collector.")
重要提示:上述代码确保在本教程中,追踪数据将默认发送到由 px.launch_app() 启动的本地 Phoenix 实例。如果您确实需要将数据发送到 Arize Cloud 或其他远程收集器,请确保 PHOENIX_COLLECTOR_ENDPOINT 和相关的认证环境变量已正确设置,并移除或注释掉删除 PHOENIX_COLLECTOR_ENDPOINT 的那行代码。
1.4 配置 OpenAI 客户端
根据前面加载的环境变量,配置 OpenAI Python 客户端。arize-phoenix 使用了 opentelemetry 库 hook 了某些主流库调用 LLM 的实现,所以在默认情况下只需提前初始化 instrumentor 即可实现自动记录。
# 从环境变量获取 OpenAI API 密钥
openai.api_key = os.getenv("OPENAI_API_KEY")
# 从环境变量获取 OpenAI API 基础 URL,如果未设置,则默认为 OpenAI 官方 API 地址
openai.api_base = os.getenv("OPENAI_BASE_URL", "https://api.openai.com/v1")
logger.info(f"OpenAI client configured with API base: {openai.api_base}")
1.5 初始化 Instrumentor
Phoenix 利用 OpenInference 规范与 OpenTelemetry 框架集成,以实现对 LLM 调用的自动追踪。核心步骤是初始化并注册一个 "Instrumentor"。Instrumentor 是一种特殊工具,它会自动 "检测"(instrument)您代码中对特定库(如 OpenAI, LangChain)的调用,捕获关于这些调用的详细信息(例如,输入数据、输出数据、执行时间、token 使用量等),然后将这些信息作为结构化的追踪数据(称为 "spans")发送到配置好的收集器(在本例中是本地 Phoenix 应用)。
我们定义一个辅助函数 initialize_instrumentor,它可以根据您使用的 LLM 框架(如 OpenAI、LangChain 或 LlamaIndex)来初始化和配置相应的 Instrumentor。
首先,定义一个枚举类来表示支持的框架:
class Framework(Enum):
OPENAI = "openai"
LANGCHAIN = "langchain"
LLAMA_INDEX = "llama_index"
然后,定义初始化函数:
def initialize_instrumentor(project_name: str, framework: Framework = Framework.OPENAI):
"""
初始化指定框架的 OpenTelemetry Instrumentor,并将其注册到 Phoenix。
参数:
project_name (str): 在 Phoenix UI 中显示的项目名称,用于组织追踪数据。
framework (Framework): 使用的 LLM 框架 (Framework.OPENAI, Framework.LANGCHAIN, etc.)。
默认为 OpenAI。
返回:
opentelemetry.trace.Tracer: 一个 Tracer 实例,可用于在代码中手动创建自定义的追踪 spans。
"""
# 调用 phoenix.otel.register 来设置 OpenTelemetry TracerProvider。
# project_name 参数会将所有追踪数据关联到 Phoenix UI 中的同名项目下。
tracer_provider = register(
project_name=project_name
)
# 根据传入的 framework 参数,选择并初始化相应的 OpenInference Instrumentor。
# .instrument(tracer_provider=tracer_provider) 会将这个 instrumentor 激活,
# 使其开始监听和记录相应框架的 LLM 调用。
if framework == Framework.LANGCHAIN:
from openinference.instrumentation.langchain import LangChainInstrumentor
LangChainInstrumentor().instrument(tracer_provider=tracer_provider)
logger.info(f"LangChainInstrumentor initialized for project '{project_name}'.")
elif framework == Framework.LLAMA_INDEX:
from openinference.instrumentation.llama_index import LlamaIndexInstrumentor
LlamaIndexInstrumentor().instrument(tracer_provider=tracer_provider)
logger.info(f"LlamaIndexInstrumentor initialized for project '{project_name}'.")
else: # 默认为 OpenAI
from openinference.instrumentation.openai import OpenAIInstrumentor
OpenAIInstrumentor().instrument(tracer_provider=tracer_provider)
logger.info(f"OpenAIInstrumentor initialized for project '{project_name}'.")
# 从 tracer_provider 获取一个 Tracer 实例。
# 这个 tracer 可以用于在您的代码中手动创建和管理自定义的 spans,
# 例如,追踪一个包含多个 LLM 调用的复杂业务逻辑单元。
tracer = tracer_provider.get_tracer(__name__) # 使用当前模块名作为 tracer 的名称
return tracer
当您调用 initialize_instrumentor 时,通常会在控制台看到 OpenTelemetry 的相关日志,确认追踪系统已启动,并指明数据将发送到哪个收集器端点(默认为本地的 localhost:4317)。
# 示例输出可能如下:
# 🔭 OpenTelemetry Tracing Details 🔭
# | Phoenix Project: your-project-name
# | Span Processor: SimpleSpanProcessor
# | Collector Endpoint: localhost:4317
# ...
# INFO:__main__:OpenAIInstrumentor initialized for project 'your-project-name'.
完成这些初始化步骤后,Phoenix 环境就绪,可以开始追踪 LLM 应用的行为了。
2. LLM 调用追踪 (Track)
Phoenix 最核心和基础的功能之一就是追踪(Track)LLM 的调用和交互过程。这使得开发者能够深入了解模型在运行时的具体行为,例如它接收了什么输入,生成了什么输出,花费了多长时间,以及消耗了多少资源(如 tokens)。这些信息对于调试问题、分析性能瓶颈、收集评估数据以及优化模型和 Prompt 都至关重要。
2.1 基础调用追踪
一旦对应框架的 Instrumentor 被成功初始化(如上一节所述),Phoenix 就能自动捕获该框架下 LLM 的调用信息,无需在每次调用时手动添加代码。
2.1.1 OpenAI
以 OpenAI 为例,在 initialize_instrumentor 函数中为 OpenAI 框架初始化 Instrumentor 后,所有标准的 OpenAI API 调用(例如 openai.chat.completions.create)都会被自动记录。
首先,我们为 OpenAI 的追踪创建一个专门的项目,并初始化 Instrumentor:
# 为 OpenAI 调用追踪设定一个项目名称,并在 Phoenix UI 中显示
openai_project_name = "my-openai-playground"
tracer_openai = initialize_instrumentor(openai_project_name, Framework.OPENAI)
现在,执行一次标准的 OpenAI API 调用:
try:
logger.info("Making an OpenAI API call to test tracing...")
response_openai = openai.chat.completions.create(
model="gpt-4o-mini", # 确保您有权限使用此模型,或替换为例如 "gpt-3.5-turbo"
messages=[
{"role": "system", "content": "You are a helpful assistant that provides concise answers."},
{"role": "user", "content": "What is the capital of France?"},
],
temperature=0.7,
)
# 打印模型响应内容
assistant_message = response_openai.choices[0].message.content
logger.info(f"OpenAI Response: {assistant_message}")
except Exception as e:
logger.error(f"Error during OpenAI API call: {e}")
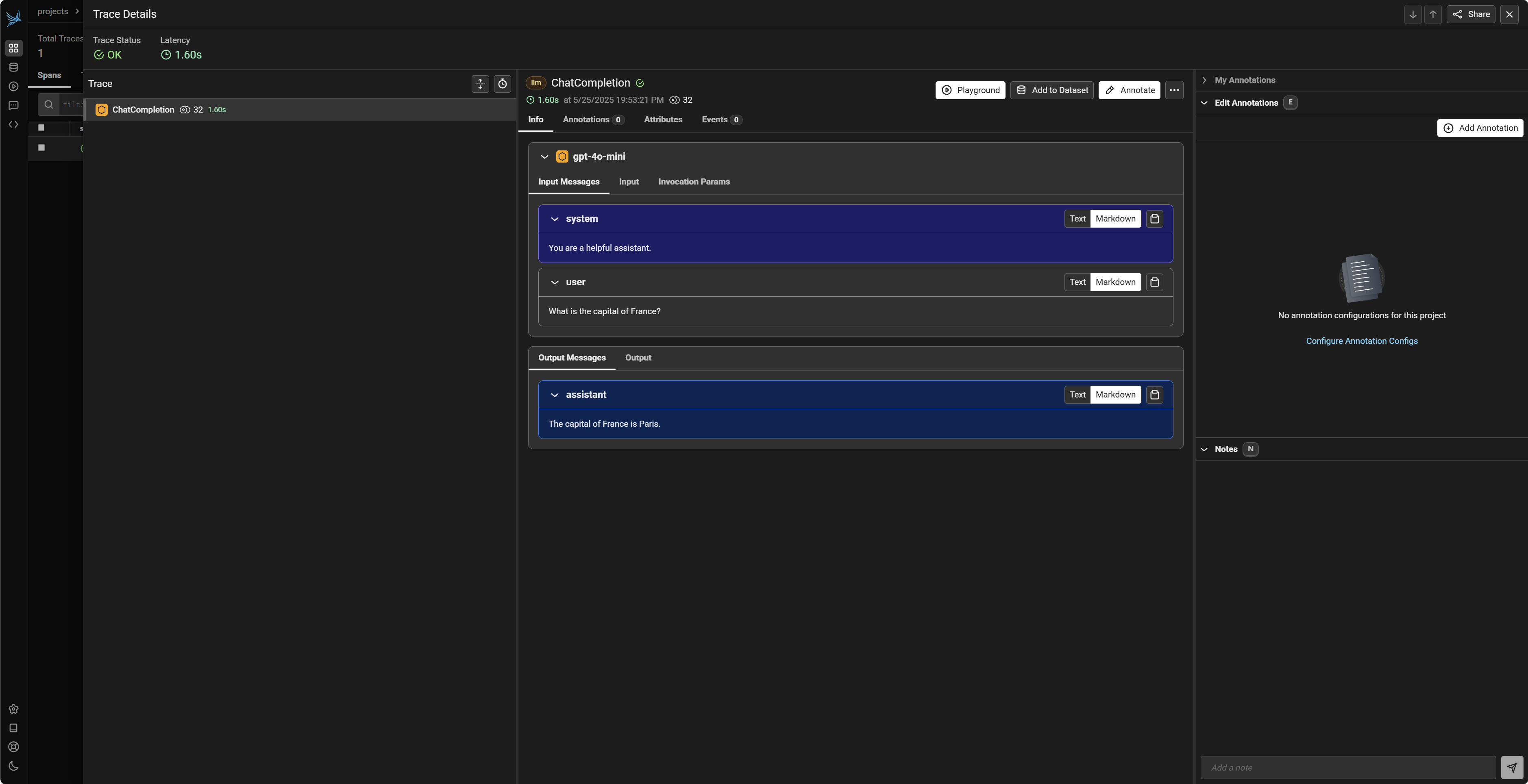
执行完毕后,您可以刷新之前打开的 Phoenix UI 界面 (通常是 http://localhost:6006/)。在界面的 "Traces" 或类似标签页下,您应该能找到名为 my-openai-playground(或您指定的项目名)的项目。点击进入该项目,您将看到刚才那次 OpenAI 调用的详细追踪记录。这些记录通常包括:
- Trace ID 和 Span ID:用于唯一标识这次调用链和具体操作。
- Input/Prompt:发送给模型的完整输入信息(包括
messages列表)。 - Output/Response:模型返回的完整响应内容。
- Model Name:使用的具体模型(如
gpt-4o-mini)。 - Token Counts:输入 token 数、输出 token 数、总 token 数。
- Latency:调用的持续时间。
- Timestamps:调用的开始和结束时间。
- Metadata:其他相关的元数据,如温度参数
temperature等。
这些信息对于理解单次 LLM 调用的细节非常有帮助。
2.1.2 LangChain
对于 LangChain 框架,追踪方式与 OpenAI 类似。首先需要为 LangChain 初始化其专属的 Instrumentor。
langchain_project_name = "my-langchain-app"
tracer_langchain = initialize_instrumentor(langchain_project_name, Framework.LANGCHAIN)
然后,使用 LangChain 的方式调用 LLM。这里我们以 ChatOpenAI 为例:
from langchain_openai import ChatOpenAI
try:
logger.info("Initializing LangChain ChatOpenAI model for tracing...")
lc_chat_model = ChatOpenAI(
model_name="gpt-4o-mini",
openai_api_key=os.getenv("OPENAI_API_KEY"),
openai_api_base=os.getenv("OPENAI_BASE_URL"),
temperature=0.7
)
logger.info("Making a LangChain LLM call...")
# 使用 LangChain 的 invoke 方法进行调用
response_langchain = lc_chat_model.invoke(
[
{"role": "system", "content": "You are a helpful assistant that speaks Chinese."},
{"role": "user", "content": "中国的首都是什么?"}, # "What is the capital of China?"
]
)
logger.info(f"LangChain Response: {response_langchain.content}")
except Exception as e:
logger.error(f"Error during LangChain operation: {e}")
注意:LangChain 的 API 和推荐的导入方式(例如 ChatOpenAI 的位置)可能会随着版本更新而变化。请确保您使用的导入路径和类名与您安装的 LangChain 版本兼容。执行后,同样可以在 Phoenix UI 的 my-langchain-app 项目下找到这次 LangChain 调用的追踪数据。Phoenix 会捕获 LangChain 内部对底层 LLM(如此处的 OpenAI)的实际调用。
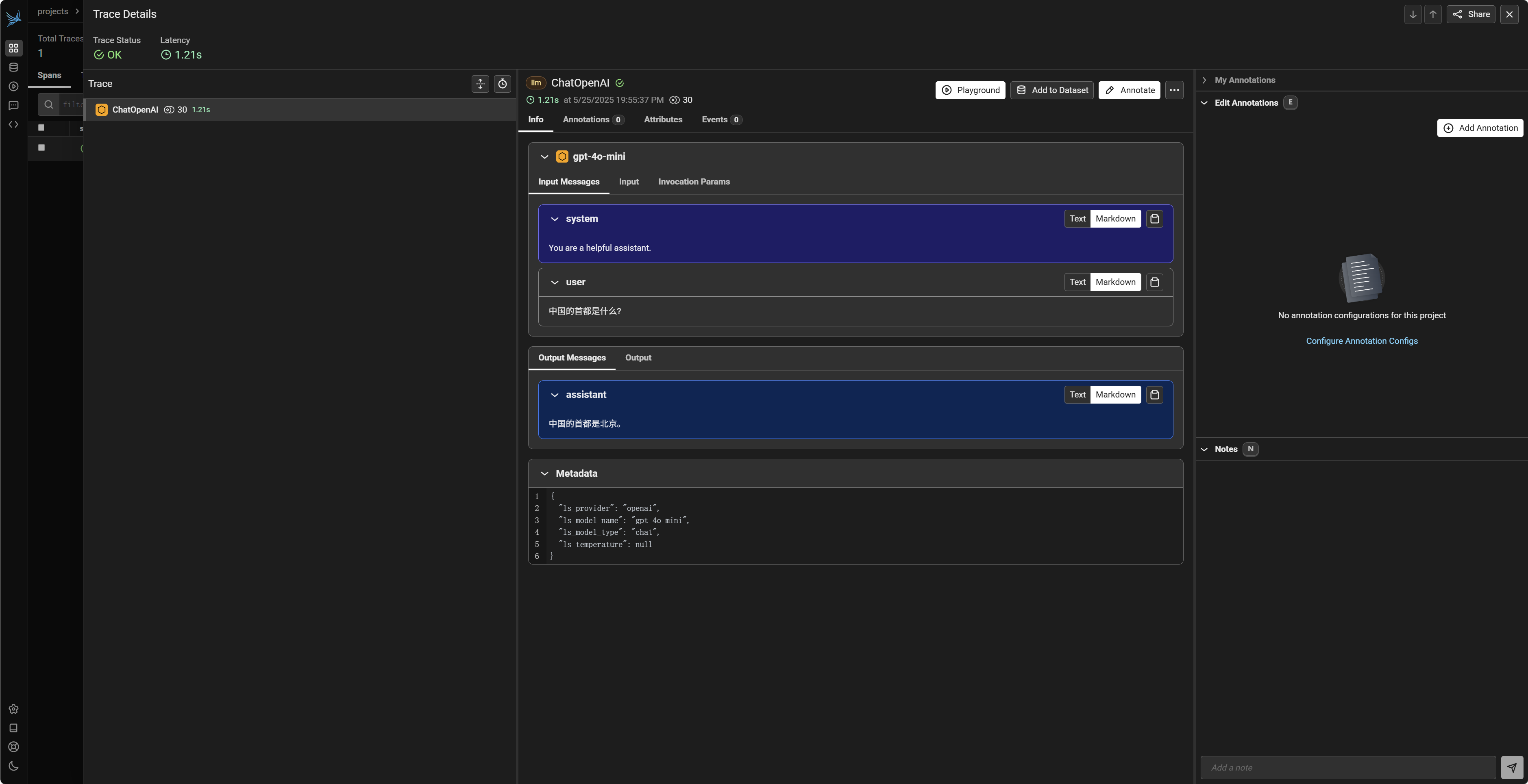
2.1.3 Langgraph
Langgraph 是 LangChain 生态中用于构建复杂、有状态的 Agent 和多步骤流程的库。当 Langgraph 中的节点执行包含 LangChain LLM 组件(如 ChatOpenAI)的调用时,如果 LangChain Instrumentor 已被正确初始化,这些底层的 LLM 调用也会被 Phoenix 自动追踪。
首先,确保 LangChain Instrumentor 已经为 Langgraph 的使用场景初始化。我们可以复用上一步为 LangChain 初始化的 tracer_langchain,或者为 Langgraph 创建一个新项目。
# 如果之前没有为 LangChain 初始化,或者想用新项目,则调用:
# langgraph_project_name = "my-langgraph-flow"
# tracer_langgraph = initialize_instrumentor(langgraph_project_name, Framework.LANGCHAIN)
# 否则,可以认为之前的 LangChain 初始化已覆盖此场景。
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
# 定义 Agent 的状态
class MyAgentState(TypedDict):
input_query: str
intermediate_results: list
final_answer: str
# 定义图中的节点
# 节点1: 初步处理输入
def process_initial_query(state: MyAgentState):
logger.info(f"--- Langgraph Node: process_initial_query with input: {state['input_query']} ---")
# 模拟一个 LLM 调用来理解或改写查询
# lc_chat_model = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# processed_query = lc_chat_model.invoke(
# [SystemMessage(content="Rewrite the user query to be clearer."), HumanMessage(content=state['input_query'])]
# ).content
processed_query = f"Processed: {state['input_query']}" # 模拟无 LLM 调用的处理
return {"intermediate_results": [("initial_processing", processed_query)]}
# 节点2: 基于处理后的查询生成答案 (这里会包含一个实际的 LLM 调用)
def generate_final_answer(state: MyAgentState):
logger.info(f"--- Langgraph Node: generate_final_answer ---")
current_context = state["intermediate_results"][-1][1]
# 实际的 LLM 调用
lc_chat_model_for_answer = ChatOpenAI(model_name="gpt-4o-mini", temperature=0.7)
final_response_obj = lc_chat_model_for_answer.invoke(
[
SystemMessage(content="You are a helpful Q&A bot."),
HumanMessage(content=f"Based on the context '{current_context}', answer the original query."),
]
)
return {"final_answer": final_response_obj.content}
# 构建图
workflow_builder = StateGraph(MyAgentState)
workflow_builder.add_node("initial_processor", process_initial_query)
workflow_builder.add_node("answer_generator", generate_final_answer)
workflow_builder.add_edge(START, "initial_processor")
workflow_builder.add_edge("initial_processor", "answer_generator")
workflow_builder.add_edge("answer_generator", END)
app_graph = workflow_builder.compile()
# 执行图
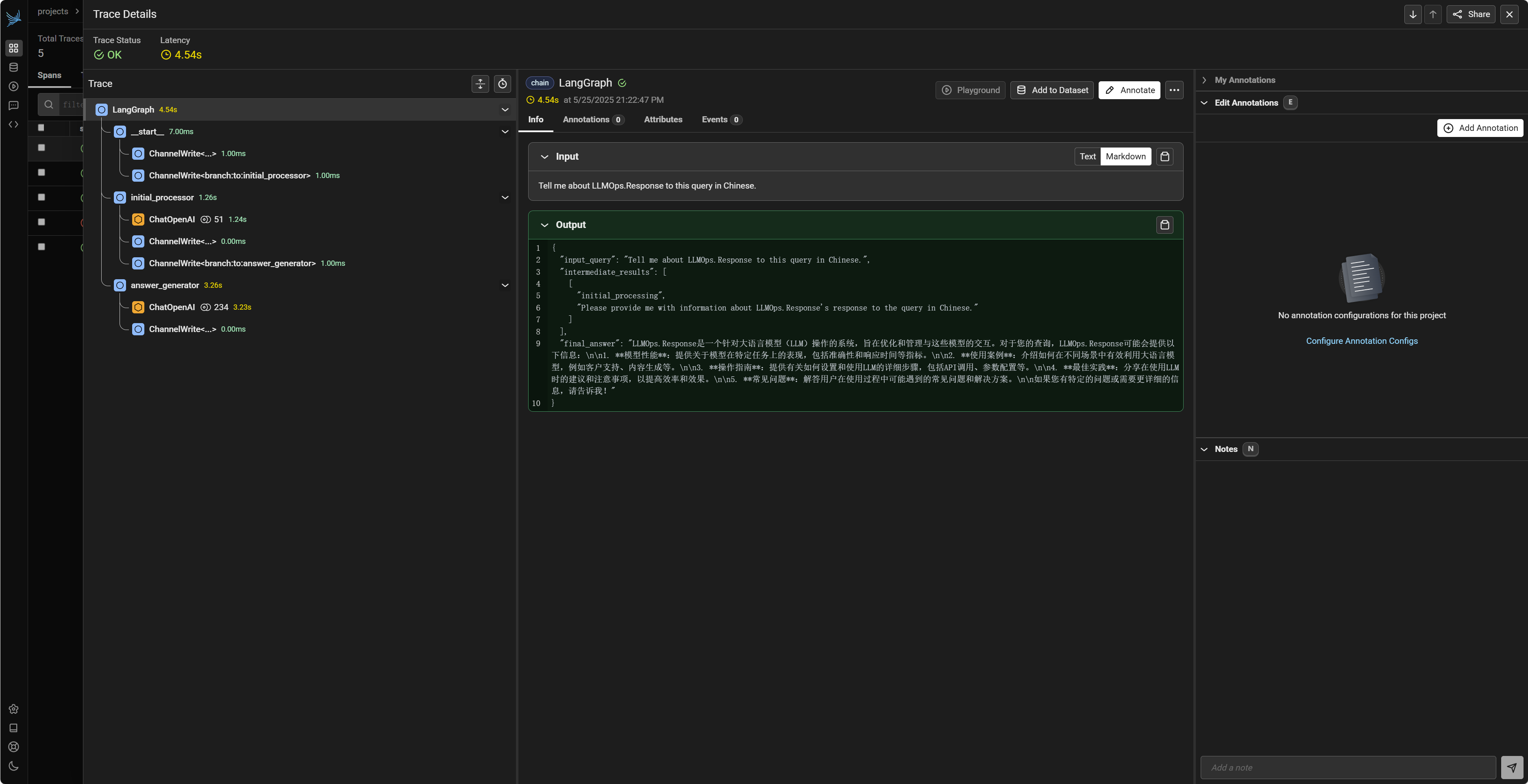
initial_graph_input = {"input_query": "Tell me about LLMOps."}
try:
logger.info(f"Running Langgraph graph with input: {initial_graph_input}")
# stream_mode="values" 会返回每个节点执行后的完整状态更新
for event_output in app_graph.stream(initial_graph_input, stream_mode="values"):
logger.info(f"Langgraph stream output: {event_output}")
# 最后一个事件通常包含最终状态
if END in event_output: # 或者检查特定key,如 'final_answer'
logger.info(f"Langgraph Final Answer: {event_output[END].get('final_answer', 'N/A')}")
except Exception as e:
logger.error(f"Error running Langgraph graph: {e}")
在上述 generate_final_answer 节点中,对 lc_chat_model_for_answer.invoke 的调用会被 Phoenix 追踪到,并记录在 my-langgraph-flow (或您选择的 LangChain 项目) 下。Phoenix UI 中的 Trace 视图通常能将 Langgraph 的多个步骤(如果每个步骤都有 LLM 调用)关联起来,形成一个完整的执行链路。
2.1.4 LlamaIndex
LlamaIndex 是一个流行的数据框架,专为构建基于 LLM 的应用(特别是 RAG 系统)而设计。Phoenix 同样可以追踪 LlamaIndex 内部发生的 LLM 调用和 Embedding 模型调用。
首先,为 LlamaIndex 初始化 Instrumentor:
# 为 LlamaIndex 调用追踪设定一个项目名称
llamaindex_project_name = "my-llamaindex-rag"
tracer_llamaindex = initialize_instrumentor(llamaindex_project_name, Framework.LLAMA_INDEX)
接下来,我们演示一个简单的 LlamaIndex RAG 流程,并观察其追踪情况:
from llama_index.core.chat_engine import SimpleChatEngine
from llama_index.llms.openai import OpenAI as LlamaOpenAI
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings as LlamaIndexSettings
from llama_index.embeddings.openai import OpenAIEmbedding as LlamaOpenAIEmbedding
# 配置 LlamaIndex 使用的 LLM 和 Embedding 模型
try:
logger.info("Configuring LlamaIndex LLM and Embedding models...")
# LLM 配置
li_llm_instance = LlamaOpenAI(
model="gpt-4o-mini",
api_base=os.getenv("OPENAI_BASE_URL"),
api_key=os.getenv("OPENAI_API_KEY")
)
# Embedding 模型配置
li_embed_model_instance = LlamaOpenAIEmbedding(
model="text-embedding-ada-002", # 常用的小型 Embedding 模型
api_base=os.getenv("OPENAI_BASE_URL"),
api_key=os.getenv("OPENAI_API_KEY")
)
# 在 LlamaIndex 中设置全局 LLM 和 Embedding 模型
# (注意:LlamaIndex 的配置方式可能随版本变化,请参考官方文档)
LlamaIndexSettings.llm = li_llm_instance
LlamaIndexSettings.embed_model = li_embed_model_instance
# 1. 简单聊天引擎 (不涉及 RAG,直接调用 LLM)
logger.info("Testing LlamaIndex SimpleChatEngine...")
simple_chat_engine = SimpleChatEngine.from_defaults(system_prompt="You are a helpful geography expert.")
chat_response = simple_chat_engine.chat("Which continent is Egypt in?")
logger.info(f"LlamaIndex SimpleChatEngine Response: {chat_response.response}")
print(f"LlamaIndex SimpleChatEngine Response: {chat_response.response}")
# 2. 简单 RAG 流程
logger.info("Testing LlamaIndex RAG pipeline...")
# 准备数据目录和文件 (如果不存在则创建)
rag_data_dir = "../data/llamaindex_sample_docs/"
if not os.path.exists(rag_data_dir):
os.makedirs(rag_data_dir)
with open(os.path.join(rag_data_dir, "phoenix_info.txt"), "w", encoding="utf-8") as f:
f.write("Arize Phoenix is an open-source ML observability library. It helps in evaluating and troubleshooting LLM applications.")
# 加载文档
documents = SimpleDirectoryReader(input_dir=rag_data_dir).load_data()
# 创建向量索引 (此步骤会调用 Embedding 模型)
logger.info("Creating VectorStoreIndex (will call embedding model)...")
index = VectorStoreIndex.from_documents(documents)
# 创建查询引擎 (Query Engine)
query_engine = index.as_query_engine() # 默认使用全局设置的 LLM
# 执行查询 (此步骤会先进行检索,然后调用 LLM 进行综合回答)
logger.info("Querying RAG engine (will call LLM for generation)...")
rag_query = "What is Arize Phoenix used for?"
rag_response = query_engine.query(rag_query)
logger.info(f"LlamaIndex RAG Response: {rag_response.response}")
print(f"LlamaIndex RAG Response for '{rag_query}': {rag_response.response}")
except FileNotFoundError:
logger.warning(f"Skipping LlamaIndex RAG example: Data directory '{rag_data_dir}' not found.")
except Exception as e:
logger.error(f"Error during LlamaIndex operation: {e}")
注意:LlamaIndex 的 API 和推荐配置方式(如 ServiceContext vs Settings)会随版本演进。请务必参考您所使用的 LlamaIndex 版本的官方文档。
执行上述代码后,在 Phoenix UI 的 my-llamaindex-rag 项目下,您应该能看到:
SimpleChatEngine的 LLM 调用。- 创建
VectorStoreIndex时,对 Embedding 模型(如text-embedding-ada-002)的调用,用于将文档转换为向量。 - 执行
query_engine.query时,可能首先有对 Embedding 模型的调用(将查询文本转换为向量),然后是检索步骤(这部分是否被追踪取决于 LlamaIndex Instrumentor 的具体实现和您的 LlamaIndex 版本),最后是对 LLM(如gpt-4o-mini)的调用,用于根据检索到的上下文生成最终答案。

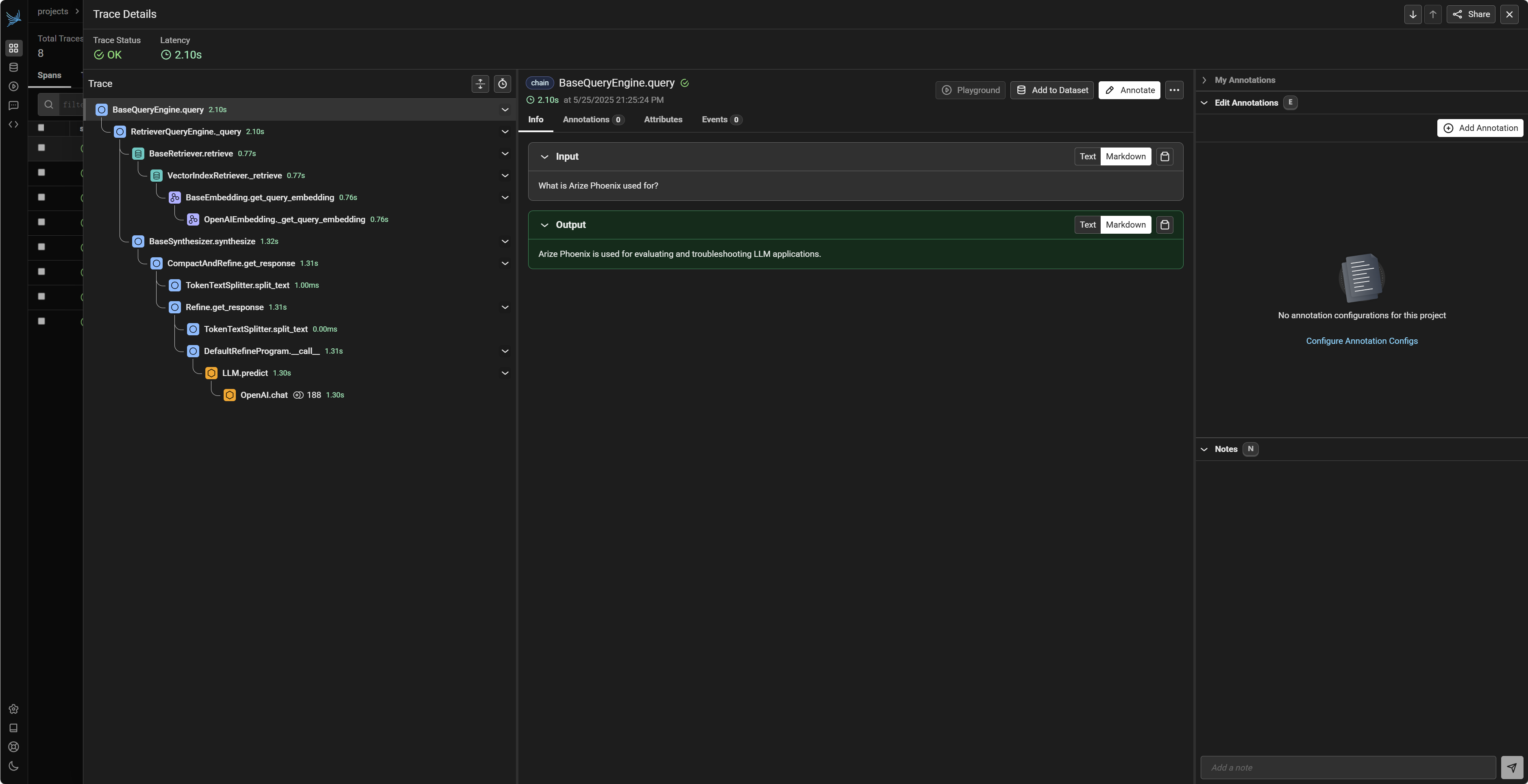
Phoenix 对 LlamaIndex 的追踪有助于理解 RAG 应用中各个组件的性能和行为。
2.2 Session (会话) 追踪
在许多 LLM 应用中,用户与模型的交互并非一次性的,而是以多轮对话(即一个“会话”或“Session”)的形式进行。Phoenix 提供了将会话中的多次 LLM 调用关联到同一个 session_id 的能力。这对于分析整个对话的连贯性、上下文依赖、用户意图变化以及长期用户体验至关重要。
openinference.instrumentation 模块中的 using_session 上下文管理器是实现会话追踪的关键。
from opentelemetry.trace import Status, StatusCode # 用于设置 Span 的状态
from openinference.instrumentation import using_session # 导入会话追踪上下文管理器
from opentelemetry import trace
from openinference.semconv.trace import SpanAttributes
from openai.types.chat import ChatCompletionMessage
# session_project_name = "my-interactive-chat-agent"
# interactive_tracer = initialize_instrumentor(session_project_name, Framework.OPENAI)
# 为当前会话生成一个唯一的 ID
current_session_id = str(uuid.uuid4())
logger.info(f"Initializing new chat session. Session ID: {current_session_id}")
print(f"Initializing new chat session. Session ID: {current_session_id}")
tracer = trace.get_tracer(__name__) # 获取 Tracer 实例,确保函数中调用得到的 current_span 是正确的
# 定义一个函数来处理单个会话回合 (turn)
# 使用 @tracer.start_as_current_span 装饰器,为每次调用此函数创建一个父 Span
@tracer.start_as_current_span(
name="process_chat_turn", # Span 的名称,描述了这个函数的功能
attributes={
SpanAttributes.OPENINFERENCE_SPAN_KIND: "agent" # 表明这个 Span 代表一个 Agent 的处理逻辑
}
)
def handle_chat_turn(
full_message_history: list[dict], # 包含系统消息和所有用户/助手消息的列表
session_id_str: str
) -> dict: # 返回一个代表助手消息的字典
"""
处理一轮对话,调用 LLM 获取回复,并记录相关的追踪信息。
"""
current_turn_span = trace.get_current_span() # 获取由装饰器创建的当前 Span
print(current_turn_span.get_span_context()) # 打印当前 Span 的 trace ID
# 设置会话 ID 到当前回合的 Span
current_turn_span.set_attribute(SpanAttributes.SESSION_ID, session_id_str)
# 记录当前回合的输入 (通常是最后一条用户消息)
user_input_for_turn = ""
if full_message_history and full_message_history[-1].get("role") == "user":
user_input_for_turn = full_message_history[-1].get("content", "")
current_turn_span.set_attribute(SpanAttributes.INPUT_VALUE, user_input_for_turn)
logger.info(f"Processing turn for session {session_id_str}. User input: '{user_input_for_turn}'")
# 使用 `using_session` 上下文管理器确保 session_id 传播到内部的 LLM 调用 Span
llm_response_message_obj: ChatCompletionMessage
try:
with using_session(session_id=session_id_str):
# 调用 OpenAI LLM
openai_response = openai.chat.completions.create(
model="gpt-4o-mini",
messages=full_message_history, # 传递完整的对话历史
temperature=0.7,
)
llm_response_message_obj = openai_response.choices[0].message
# 记录当前回合的输出
assistant_response_content = llm_response_message_obj.content
current_turn_span.set_attribute(SpanAttributes.OUTPUT_VALUE, assistant_response_content)
logger.info(f"LLM response received for session {session_id_str}: '{assistant_response_content}'")
# 返回 LLM 响应消息对象转换成的字典,以便添加到外部的对话历史列表中
return llm_response_message_obj.model_dump(exclude_none=True)
except Exception as e:
logger.error(f"Error during LLM call in handle_chat_turn (session {session_id_str}): {e}")
# 如果出错,设置当前回合 Span 的状态为错误,并记录错误信息
current_turn_span.set_status(Status(StatusCode.ERROR, description=str(e)))
current_turn_span.record_exception(e) # 记录异常到 Span
# 可以选择抛出异常或返回一个错误指示
return {"role": "assistant", "content": f"Sorry, an error occurred: {str(e)}"}
# --- 主对话流程 ---
# 初始化对话历史
conversation_history_turns: list[dict] = [
{"role": "system", "content": "You are a helpful assistant that can remember user information across turns."}
]
# --- 会话第一轮 ---
print("\n--- Chat Session: Turn 1 ---")
user_query_turn1 = "hi! im bob"
conversation_history_turns.append({"role": "user", "content": user_query_turn1})
print(f"User: {user_query_turn1}")
assistant_reply_dict_turn1 = handle_chat_turn(
full_message_history=conversation_history_turns,
session_id_str=current_session_id
)
conversation_history_turns.append(assistant_reply_dict_turn1)
print(f"Assistant: {assistant_reply_dict_turn1.get('content')}")
# --- 会话第二轮 ---
print("\n--- Chat Session: Turn 2 ---")
user_query_turn2 = "what's my name?"
conversation_history_turns.append({"role": "user", "content": user_query_turn2})
print(f"User: {user_query_turn2}")
assistant_reply_dict_turn2 = handle_chat_turn(
full_message_history=conversation_history_turns,
session_id_str=current_session_id
)
conversation_history_turns.append(assistant_reply_dict_turn2)
print(f"Assistant: {assistant_reply_dict_turn2.get('content')}")
logger.info(f"Chat session {current_session_id} concluded. Total turns (user + assistant): {len(conversation_history_turns) -1 }.")
注意装饰器使用的类 tracer 必须通过 trace.get_tracer 方法得到,否则函数中的 trace.get_current_span() 无法获取正确的 span 从而会导致对话页面无法正常展示。
执行上述代码后,在 Phoenix UI 的 my-conversational-ai 项目中:
- 您会找到一个名为
user_chat_session_<session_id>的父 Span。 - 在这个父 Span 下,会嵌套着两次对
openai.chat.completions.create的调用所产生的子 Spans。 - 所有这些 Spans(父 Span 和子 Spans)都会带有一个 session.id 属性,其值等于 current_session_id。
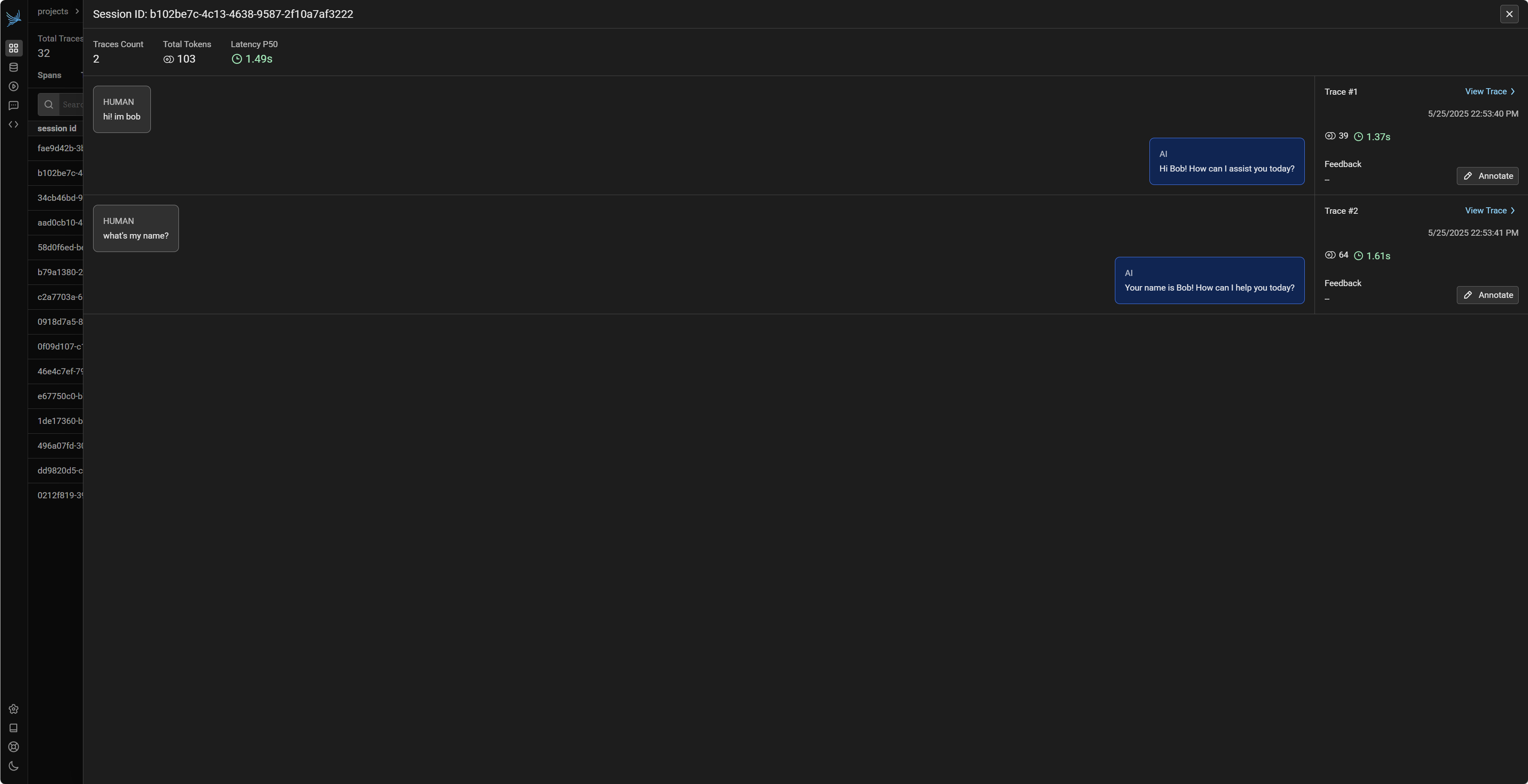
这使得在 Phoenix UI 中筛选和查看特定用户会话的所有相关 LLM 交互变得非常方便。您可以点击父 Span 查看整个会话的概览和手动添加的事件,也可以深入到每个子 Span 查看单次 LLM 调用的详细信息。
3. Prompt 管理与版本化
在开发和迭代 LLM 应用时,提示词(Prompt)的设计、测试和版本控制是至关重要的环节。一个好的 Prompt 能够显著提升模型在特定任务上的表现。Phoenix 提供了强大的 Prompt 管理功能,允许开发者:
- 存储和组织 Prompt 模板:集中管理所有 Prompt。
- 版本化 Prompt:追踪 Prompt 的修改历史,方便回滚或比较不同版本的效果。
- 参数化 Prompt:使用模板语言(如 Mustache 的
{{variable}}格式)定义可复用的 Prompt,并在运行时填充变量。 - 共享和协作:团队成员可以共享和协作编辑 Prompt。
首先,我们需要获取一个 Phoenix 客户端实例,它将用于与 Phoenix 后端服务(无论是本地运行的还是云端的)进行交互,以执行 Prompt 的创建、检索等操作。
client = px.Client()
Prompt 模板是包含固定文本和动态占位符的字符串。Phoenix 默认使用 Mustache 模板语法,即 {{variable_name}} 的形式来定义占位符。这些占位符可以在运行时被具体的值动态替换,从而生成最终发送给 LLM 的完整 Prompt。
prompt_template_string = """\
You are an expert {{domain_expert_role}} with deep knowledge in {{topic}}.
Your task is to explain the concept of '{{concept_to_explain}}' to a beginner.
Please provide a clear, concise, and easy-to-understand explanation.
The explanation should be in {{language}}.
Include a simple analogy if possible.
Concept: {{concept_to_explain}}
为了在 Phoenix 系统中管理和识别这个 Prompt 模板,我们需要为其指定一个名称。这个名称在 Phoenix Prompt 注册表中应该是唯一的(或者至少在您的项目中是唯一的,以便于区分)。一个好的实践是使用具有描述性的名称,并可以考虑添加 UUID 的一部分来确保其全局唯一性,特别是在多人协作或有多个相似 Prompt 的场景下。
# 建议使用有意义且唯一的名称,可以加上 UUID 的一部分来确保在多次运行时名称不冲突。
prompt_registry_name = f"beginner-concept-explainer-tutorial-{str(uuid.uuid4())[:4]}"
logger.info(f"Defining a new prompt named: {prompt_registry_name}")
# 创建 Prompt (或为其添加新版本)
try:
# PromptVersion 对象封装了 Prompt 的所有细节
prompt_v1_definition = PromptVersion(
[
{"role": "system", "content": "You are a helpful and patient teaching assistant."},
{"role": "user", "content": prompt_template_string} # 将模板字符串作为用户消息内容
],
model_name="gpt-4o-mini", # 指定此 Prompt 版本推荐使用的模型
)
# 将 PromptVersion 保存到 Phoenix
prompt_v1_instance = client.prompts.create(
name=prompt_registry_name,
version=prompt_v1_definition,
prompt_description="V1: Explains a concept to a beginner. (Tutorial)"
)
logger.info(f"Prompt '{prompt_registry_name}' - Version 1 created. Version ID: {prompt_v1_instance.id}")
print(f"Prompt '{prompt_registry_name}' - Version 1 created. Version ID: {prompt_v1_instance.id}")
except Exception as e:
logger.error(f"Error creating Prompt Version 1: {e}")
print(f"Error creating Prompt Version 1: {e}")
prompt_v1_instance = None # 用于后续安全检查
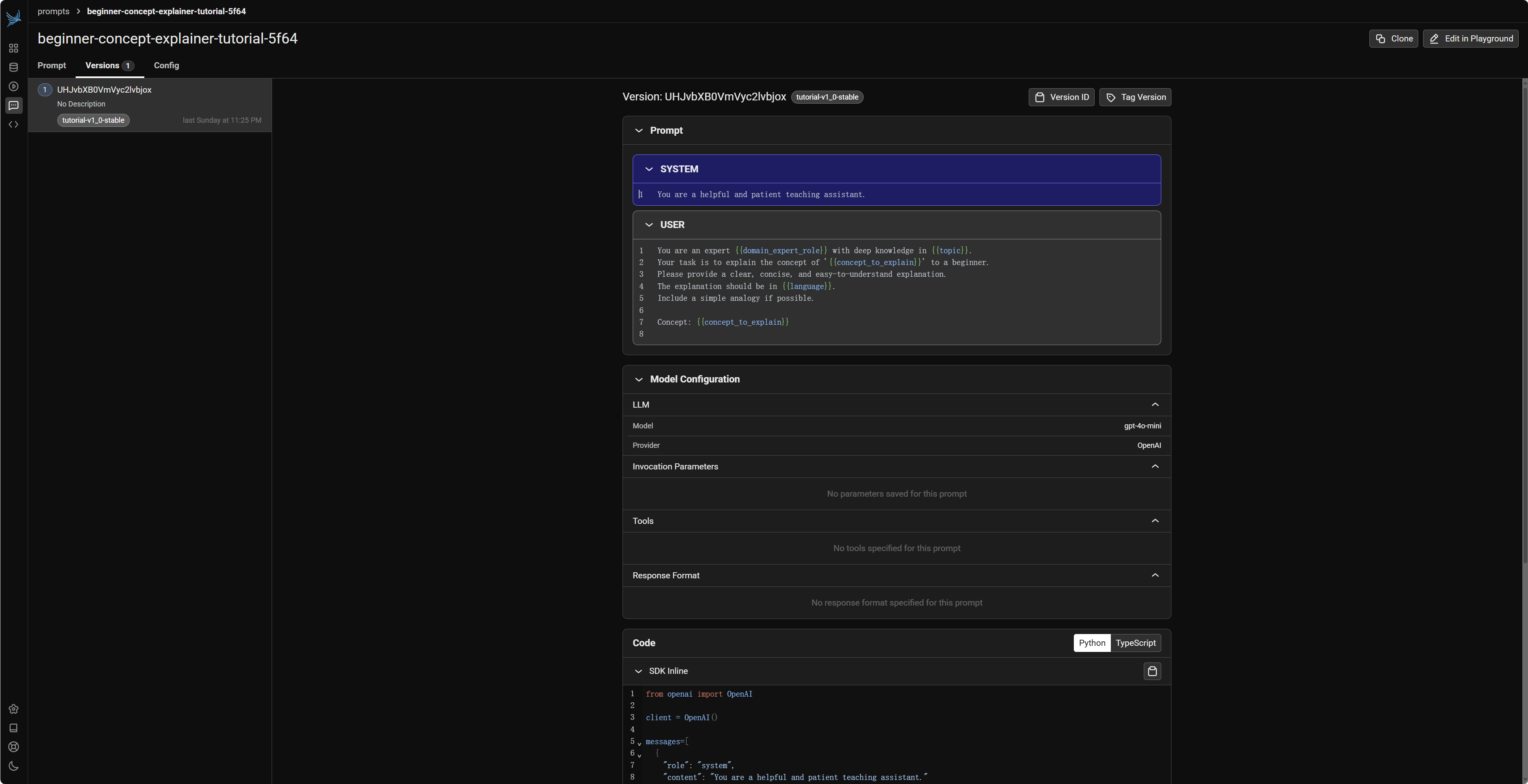
创建 Prompt 后,我们可以通过其全局名称(获取最新版本)或特定的 PromptVersion ID 来从 Phoenix 中检索它。检索到的 PromptVersion 对象可以使用 .format() 方法来填充模板变量,生成可以直接用于 LLM API 调用的负载(payload)。
# 获取已存储的 Prompt 并格式化
if prompt_v1_instance: # 确保之前的 Prompt 创建成功
try:
# 通过全局名称获取最新版本的 PromptVersion
retrieved_prompt_by_name = client.prompts.get(
prompt_identifier=prompt_registry_name
)
logger.info(
f"Retrieved latest version of '{prompt_registry_name}'. ID: {retrieved_prompt_by_name.id}"
)
# 通过 Version ID 获取特定版本
retrieved_prompt_by_id = client.prompts.get(
prompt_version_id=prompt_v1_instance.id
)
logger.info(f"Retrieved prompt by Version ID '{prompt_v1_instance.id}'.")
# 格式化 Prompt (填充模板变量)
variables_to_fill = {
"domain_expert_role": "Data Scientist",
"topic": "Machine Learning",
"concept_to_explain": "Overfitting",
"language": "English",
}
# .format() 返回一个包含 'messages' 和模型参数的字典
formatted_api_payload = retrieved_prompt_by_id.format(
variables=variables_to_fill
)
logger.info(f"Formatted Prompt Payload: {formatted_api_payload}")
print(
f"\nFormatted Prompt Payload (for LLM API call):\n{json.dumps(dict(formatted_api_payload), indent=4)}"
)
except Exception as e:
logger.error(f"Error retrieving or formatting prompt: {e}")
print(f"Error retrieving or formatting prompt: {e}")
最后,Phoenix 还允许为特定的 PromptVersion 添加标签(tags)。标签可以帮助您更好地组织、筛选和管理不同用途或处于不同开发阶段(如 "development", "staging", "production") 的 Prompt 版本。
if prompt_v1_instance: # 确保 PromptVersion ID 可用
try:
tag_name = "tutorial-v1_0-stable" # 只能以字母或数字开头结尾,中间可以包含下划线或连字符
tag_description = "Stable version 1.0 of the concept explainer prompt for the tutorial."
client.prompts.tags.create(
prompt_version_id=prompt_v1_instance.id,
name=tag_name,
description=tag_description,
)
logger.info(f"Tag '{tag_name}' added to prompt version '{prompt_v1_instance.id}'.")
print(f"Tag '{tag_name}' added to prompt version '{prompt_v1_instance.id}'.")
except Exception as e:
logger.error(f"Error adding tag to prompt version: {e}")
print(f"Error adding tag to prompt version: {e}")
所有通过代码创建和管理的 Prompt 及其版本、标签等信息,都可以在 Phoenix UI 的 "Prompts" 部分进行可视化查看、编辑、比较和管理。这为团队协作和 Prompt 的持续优化提供了极大的便利。
4. 数据集管理与构建
在 LLM 应用的整个生命周期中,数据集扮演着至关重要的角色。它们不仅是评估模型性能和 Prompt 效果的基准,也是模型微调(fine-tuning)和合成数据生成的基础。Phoenix 提供了强大的数据集管理功能,允许您:
- 上传和存储结构化数据:例如,包含输入样本和对应期望输出(ground truth)的表格数据。
- 版本化数据集:追踪数据集的变更历史。
- 定义数据模式(Schema):明确数据集中哪些列是输入(inputs)、哪些是期望输出(outputs)、哪些是上下文(context)等。
- 利用 LLM 生成合成数据:基于现有数据或模板,使用 LLM 批量创建新的数据样本。
4.1 上传已有数据 (Pandas DataFrame)
如果您已经拥有结构化的数据(例如,存储在 CSV 文件、数据库或直接在内存中的 Pandas DataFrame),可以非常方便地将其上传到 Phoenix 进行管理。
我们将创建一个简单的示例 DataFrame,其中包含一些城市名称(作为输入)和它们对应的国家(作为期望输出)。
# 准备示例数据
city_country_data = [
{"city_name_for_model": "Tokyo", "correct_country_answer": "日本"},
{"city_name_for_model": "Paris", "correct_country_answer": "France"},
{"city_name_for_model": "Москва", "correct_country_answer": "Россия"},
{"city_name_for_model": "Berlin", "correct_country_answer": "Deutschland"},
{"city_name_for_model": "Roma", "correct_country_answer": "Italia"},
]
source_dataframe = pd.DataFrame(city_country_data)
logger.info("Original DataFrame to be uploaded as a Phoenix Dataset:")
print("Original DataFrame for Dataset Upload:")
print(source_dataframe.head())
# 获取 Phoenix 客户端实例
client = px.Client()
# 定义数据集名称
dataset_registry_name = f"tutorial-city-to-country-eval-set-{str(uuid.uuid4())[:8]}"
logger.info(f"Target Phoenix Dataset name: {dataset_registry_name}")
接下来,使用 client.upload_dataset 方法将 DataFrame 上传到 Phoenix。在上传时,我们需要通过 input_keys 和 output_keys 参数指定 DataFrame 中的哪些列分别对应模型的输入和期望的输出(ground truth)。
# 上传数据集到 Phoenix
try:
uploaded_dataset_info = client.upload_dataset(
dataframe=source_dataframe,
dataset_name=dataset_registry_name,
input_keys=["city_name_for_model"], # 列名 'city_name_for_model' 将作为输入
output_keys=["correct_country_answer"], # 列名 'correct_country_answer' 将作为期望输出
dataset_description="Sample dataset: city names to their countries (tutorial)."
)
logger.info(f"Dataset '{dataset_registry_name}' uploaded. ID: {uploaded_dataset_info.id}, Version: {uploaded_dataset_info.version_id}")
print(f"Dataset '{dataset_registry_name}' uploaded. ID: {uploaded_dataset_info.id}, Version: {uploaded_dataset_info.version_id}")
except Exception as e:
logger.error(f"Error during dataset upload: {e}")
print(f"Error during dataset upload: {e}")
uploaded_dataset_info = None
如果您有新的数据样本,可以使用 client.append_to_dataset 将它们追加到已存在的数据集中。这通常会为该数据集创建一个新的版本。
# (可选) 追加数据到现有数据集
if uploaded_dataset_info: # 确保初始上传成功
additional_city_country_data = [
{"city_name_for_model": "London", "correct_country_answer": "United Kingdom"},
{"city_name_for_model": "Beijing", "correct_country_answer": "中国"},
]
additional_dataframe = pd.DataFrame(additional_city_country_data)
logger.info("Appending additional data to the dataset...")
try:
appended_dataset_info = client.append_to_dataset(
dataset_name=dataset_registry_name,
dataframe=additional_dataframe,
input_keys=["city_name_for_model"],
output_keys=["correct_country_answer"],
)
logger.info(f"Data appended to '{dataset_registry_name}'. New Version: {appended_dataset_info.version_id}")
print(f"Data appended to '{dataset_registry_name}'. New Version: {appended_dataset_info.version_id}")
except Exception as e:
logger.error(f"Error appending data to dataset: {e}")
print(f"Error appending data to dataset: {e}")
上传或追加数据后,我们可以通过数据集的名称从 Phoenix 中检索它,并查看其内容。Phoenix Dataset 对象可以方便地转换回 Pandas DataFrame。
# 获取和查看已上传的数据集信息
try:
retrieved_phoenix_dataset = client.get_dataset(name=dataset_registry_name)
logger.info(f"Retrieved dataset '{retrieved_phoenix_dataset.id}'. Version: {retrieved_phoenix_dataset.version_id}")
print(f"\nRetrieved dataset '{retrieved_phoenix_dataset.id}'. Version: {retrieved_phoenix_dataset.version_id}")
dataset_as_dataframe = retrieved_phoenix_dataset.as_dataframe()
if not dataset_as_dataframe.empty:
logger.info("Retrieved dataset as Pandas DataFrame (first 5 rows):")
print("\nDataset examples as DataFrame (first 5 rows):")
# 注意列名会自动加上 'inputs.' 或 'outputs.' 前缀
print(dataset_as_dataframe.head())
else:
logger.warning("Retrieved dataset is empty or could not be converted to DataFrame.")
print("Retrieved dataset is empty or could not be converted to DataFrame.")
except Exception as e:
logger.error(f"Error retrieving or converting dataset: {e}")
print(f"Error retrieving or converting dataset: {e}")
所有上传到 Phoenix 的数据集都可以在其 Web UI 的 "Datasets" 部分进行管理。您可以查看数据集的详细信息、版本历史、包含的样本数据,以及与该数据集相关的评估和实验结果。
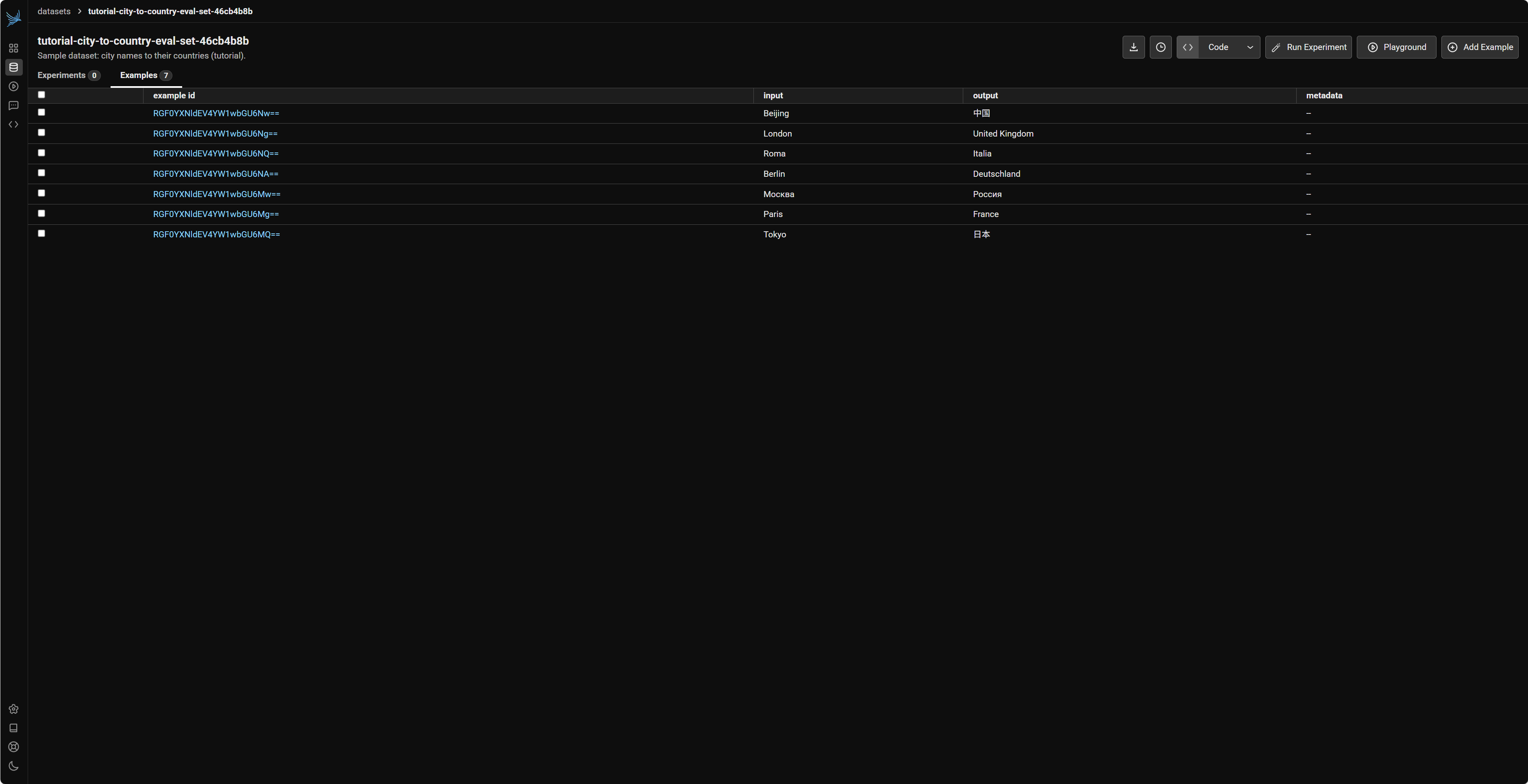
4.2 合成数据 (LLM Generate)
除了上传预先准备好的数据,Phoenix 还提供了一个非常实用的功能:llm_generate。这个函数允许您利用一个 LLM(例如 GPT-3.5-turbo 或 GPT-4)根据提供的输入数据和 Prompt 模板来批量生成新的数据。这对于快速创建评估集、生成多样化的训练样本或扩充现有数据集非常有用。
例如,我们可以根据一些简短的文档片段(作为输入),让 LLM 为每个片段生成一个相关的问题(作为输出)。
首先,准备源数据和用于生成问题的 Prompt 模板。
# 准备源数据:一些文档片段
source_document_chunks = [
{"id": "doc1", "text_content": "Arize Phoenix is an open-source library for ML observability, focusing on LLM evaluation and troubleshooting."},
{"id": "doc2", "text_content": "It supports integration with popular frameworks like OpenAI, LangChain, and LlamaIndex for automatic tracing."},
{"id": "doc3", "text_content": "Key features of Phoenix include experiment tracking, prompt management, and dataset versioning."},
]
source_chunks_df = pd.DataFrame(source_document_chunks)
logger.info("Source DataFrame for synthetic question generation:")
print("Source DataFrame for synthetic question generation:")
print(source_chunks_df)
# 定义用于生成问题的 Prompt 模板
question_generation_template = """
Based on the following context:
---------------------
{text_content}
---------------------
Please generate a single, clear, and insightful question that can be answered using ONLY the provided context.
The question should be suitable for a quiz or a test of understanding.
Output the generated question in JSON format, with a single key "generated_question".
Example: ["generated_question": "What is the main purpose of Arize Phoenix?"] but use curly braces instead of square brackets.
"""
由于 LLM 的输出是字符串,我们需要定义一个解析函数,将其安全地转换为我们期望的 Python 字典结构。
# 定义输出解析器
def json_response_parser_for_q_gen(llm_response_string: str, row_index: int):
try:
cleaned_string = llm_response_string.strip()
if cleaned_string.startswith("```json"):
cleaned_string = cleaned_string[7:]
if cleaned_string.endswith("```"):
cleaned_string = cleaned_string[:-3]
cleaned_string = cleaned_string.strip()
parsed_data = json.loads(cleaned_string)
# print(passed_data) # 调试输出,查看解析后的数据
logger.info(f"Row {row_index}: Parsed JSON for Q-gen: {parsed_data}")
if isinstance(parsed_data, dict) and "generated_question" in parsed_data:
return parsed_data
else:
logger.warning(f"Row {row_index}: Parsed JSON for Q-gen invalid. Response: '{llm_response_string}'")
return {"__error__": "Invalid JSON structure from LLM for Q-gen", "raw_response": llm_response_string}
except json.JSONDecodeError as e:
logger.error(f"Row {row_index}: JSONDecodeError for Q-gen, response '{llm_response_string}'. Error: {e}")
return {"__error__": str(e), "raw_response": llm_response_string}
现在,我们可以调用 llm_generate 函数。它会为源 DataFrame 中的每一行执行 LLM 调用,并将结果(包括原始输入、LLM 的原始输出以及解析后的字段)合并到一个新的 DataFrame 中。
# 使用 `llm_generate` 函数批量生成问题
try:
logger.info("Starting synthetic question generation using llm_generate...")
synthesized_questions_df = llm_generate(
dataframe=source_chunks_df,
template=question_generation_template,
model=OpenAIModel(
model="gpt-3.5-turbo",
base_url=openai.api_base,
api_key=openai.api_key
),
output_parser=json_response_parser_for_q_gen,
concurrency=2,
)
# (可选) 清理和筛选成功生成的数据
if '__error__' in synthesized_questions_df.columns:
successfully_generated_df = synthesized_questions_df[
synthesized_questions_df['generated_question'].notna() &
(synthesized_questions_df['__error__'].isna() | (synthesized_questions_df['__error__'] == ''))
].copy()
else:
successfully_generated_df = synthesized_questions_df[
synthesized_questions_df['generated_question'].notna()
].copy()
if not successfully_generated_df.empty:
logger.info("Successfully generated and parsed questions:")
else:
logger.warning("No questions were successfully generated or parsed.")
except Exception as e:
logger.error(f"Unexpected error during llm_generate: {e.with_traceback()}")
llm_generate 是一个非常强大的工具,它极大地简化了基于 LLM 的数据合成流程。通过精心设计 Prompt 模板和输出解析器,您可以快速构建用于各种目的(如模型评估、微调数据准备、内容生成等)的合成数据集。生成的数据同样可以利用 client.upload_dataset 上传到 Phoenix 进行统一管理和版本控制。
除此之外,llm_generate 其实还可以用于自定义评估器。
5. LLM 输出评估 (Eval)
仅仅追踪 LLM 的调用和管理数据集是不够的,我们还需要一种有效的方法来评估模型输出的质量。这对于理解模型在特定任务上的表现、发现潜在问题(如幻觉、不相关答案)、比较不同 Prompt 或模型的效果,以及驱动持续改进至关重要。Phoenix 提供了多种内置的评估器(Evaluators),它们通常利用一个更强大、更可靠的 LLM(作为“裁判模型”,例如 GPT-4 或 Claude 3 Opus)来对目标 LLM 的输出进行打分,并可以提供评估的理由或解释。
5.1 基础评估流程
让我们通过一个具体的例子来演示如何使用 Phoenix 的评估器。我们将准备一个包含以下内容的小型数据集:
ground_truth_reference: 作为事实依据或正确答案的参考文本。user_query: 用户向模型提出的问题。model_response: 目标 LLM 对用户问题给出的实际回答。
然后,我们将使用 Phoenix 的 HallucinationEvaluator(幻觉评估器)和 QAEvaluator(问答正确性评估器)来评估 model_response。
首先,准备用于评估的样本数据,并将其转换为符合 Phoenix 评估器期望列名的 DataFrame。
evaluation_samples = [
{
"id": "sample_1_factual",
"ground_truth_reference": "The Eiffel Tower, an iconic landmark in Paris, France, was designed by Gustave Eiffel and completed in 1889 for the 1889 World's Fair. It is 330 meters tall.",
"user_query": "Where is the Eiffel Tower located and when was it built?",
"model_response": "The Eiffel Tower is located in Paris, France, and it was constructed in 1889.",
},
{
"id": "sample_2_hallucination",
"ground_truth_reference": "The Great Wall of China is a series of fortifications made of stone, brick, tamped earth, wood, and other materials, generally built along an east-to-west line across the historical northern borders of China to protect the Chinese states and empires against the raids and invasions of the various nomadic groups of the Eurasian Steppe. Its total length is over 13,000 miles (21,196 km).",
"user_query": "How long is the Great Wall of China and what is its primary color?",
"model_response": "The Great Wall of China is approximately 20,000 miles long and is primarily yellow due to the desert sand.", # 长度不准确,颜色是幻觉
},
{
"id": "sample_3_incorrect_qa",
"ground_truth_reference": "The adult human body typically has 206 bones. This number can vary slightly with age (e.g., infants have more bones that later fuse) and individual anatomical variations.",
"user_query": "How many bones are in the adult human body?",
"model_response": "An adult human body has exactly 256 bones, and this number never changes.", # 数量错误,且过于绝对
},
]
source_eval_df = pd.DataFrame(evaluation_samples)
source_eval_df
转换 DataFrame 以符合 Phoenix 评估器的期望列名,Phoenix 评估器通常期望以下标准列名:
input: 用户或系统的输入/问题。output: 目标 LLM 的输出/回答。reference: 用于判断正确性或事实性的基准答案/真实信息。context: 模型在生成输出时可能依赖的上下文信息。对于幻觉检测,'context' 列的内容至关重要。
df_for_phoenix_eval = pd.DataFrame()
df_for_phoenix_eval["input"] = source_eval_df["user_query"]
df_for_phoenix_eval["output"] = source_eval_df["model_response"]
df_for_phoenix_eval["reference"] = source_eval_df["ground_truth_reference"]
df_for_phoenix_eval["context"] = source_eval_df["ground_truth_reference"]
# 保留原始ID,方便追踪
df_for_phoenix_eval["original_id"] = source_eval_df["id"]
logger.info("DataFrame prepared for Phoenix Evals (with standard column names):")
接下来,初始化我们需要的评估器。评估器本身也使用 LLM(我们称之为“裁判 LLM”)来执行评估。为了获得准确的评估结果,推荐使用能力相对较强的模型作为裁判 LLM。(比如问答时使用 gpt-4.1-mini, 评估时使用 gpt-4.1)
eval_judge_llm = OpenAIModel(model="gpt-4.1")
hallucination_checker = HallucinationEvaluator(eval_judge_llm)
qa_accuracy_checker = QAEvaluator(eval_judge_llm)
logger.info("Evaluators (HallucinationChecker, QAAccuracyChecker) initialized.")
现在,调用 run_evals 函数来批量执行评估。run_evals 会为输入 DataFrame 中的每一行数据,分别调用我们提供的所有评估器。
try:
logger.info("Starting batch evaluation with run_evals...")
hallucination_eval_df, qa_accuracy_eval_df = run_evals(
dataframe=df_for_phoenix_eval,
evaluators=[hallucination_checker, qa_accuracy_checker],
provide_explanation=True,
)
logger.info("Batch evaluation completed.")
print("\nHallucination Evaluation Results (from run_evals):")
print(hallucination_eval_df[['label', 'score', 'explanation']].head())
print("\nQA Correctness Evaluation Results (from run_evals):")
print(qa_accuracy_eval_df[['label', 'score', 'explanation']].head())
# (可选) 合并原始数据和所有评估结果
final_combined_results_df = df_for_phoenix_eval.copy()
final_combined_results_df = final_combined_results_df.join(
hallucination_eval_df[['label', 'score', 'explanation']].rename(
columns={'label': 'hallucination_label', 'score': 'hallucination_score', 'explanation': 'hallucination_explanation'}
)
)
final_combined_results_df = final_combined_results_df.join(
qa_accuracy_eval_df[['label', 'score', 'explanation']].rename(
columns={'label': 'qa_correctness_label', 'score': 'qa_correctness_score', 'explanation': 'qa_correctness_explanation'}
)
)
except Exception as e:
logger.error(f"An error occurred during the run_evals process: {e}")
当 run_evals 执行时,评估结果不会自动记录到 Phoenix。如果为了确保能在 Pheonix UI 中显示评估记录,则必须使用 Phoenix 记录的 trace 或者 span 数据集,也就是之前记录的调用数据,不能是自己新建的数据集。
6. 实验驱动的优化 (Experiment)
LLM 应用的优化是一个持续迭代的过程,通常涉及到对 Prompt 的微调、模型参数的调整,甚至更换不同的模型。为了科学地进行这些迭代并衡量其效果,结构化的实验非常关键。Phoenix 的实验(Experiment)功能为此提供了一套完整的解决方案,它允许您:
- 定义一个基准数据集(Dataset):包含一系列输入样本和(可选的)期望输出。
- 定义一个任务函数(Task Function):该函数接收数据集中的单行输入,执行您的 LLM 应用逻辑(例如,使用特定的 Prompt 和模型进行调用),并返回模型的原始输出。
- 定义一个或多个评估函数(Evaluator Functions):这些函数接收任务函数返回的模型输出和数据集中的期望输出,然后给出一个或多个评估指标(例如,准确率、相关性得分、是否符合特定格式等)。
- 运行实验:Phoenix 会自动为数据集中的每一行执行任务函数,并用所有评估函数对结果进行评估。
- 记录和比较结果:实验的详细结果(包括每次任务的输入、输出、所有评估指标)会被记录下来,方便您在 Phoenix UI 中比较不同实验(例如,使用不同 Prompt 版本或不同模型的实验)的整体性能。
让我们通过一个例子来演示如何使用 Phoenix 的实验功能来测试不同 Prompt 对模型表现的影响。
首先,准备用于实验的 Prompt 版本和数据集,为了方便,这次选择采用前面第四部分提到的城市和国家数据集,只需创建 Prompt 即可。
# Prompt 版本 1 (更简洁)
exp_prompt_v1_name = f"city_to_country_exp_prompt_v1_{str(uuid.uuid4())[:4]}"
exp_prompt_v1_template = "City: {{city_name}}. Country?"
exp_prompt_v1_params = CompletionCreateParamsBase(
model="gpt-3.5-turbo",
temperature=0.0,
messages=[{"role": "user", "content": exp_prompt_v1_template}],
)
try:
prompt_v1_obj = PromptVersion.from_openai(exp_prompt_v1_params)
exp_prompt_v1_phoenix = client.prompts.create(
name=exp_prompt_v1_name, version=prompt_v1_obj,
prompt_description="V1: Concise prompt for city-to-country experiment (gpt-3.5-turbo)"
)
logger.info(f"Experiment Prompt V1 ('{exp_prompt_v1_name}') created. Version ID: {exp_prompt_v1_phoenix.id}")
except Exception as e:
logger.error(f"Error creating experiment prompt V1: {e}")
exp_prompt_v1_phoenix = None
# Prompt 版本 2 (更详细)
exp_prompt_v2_name = f"city_to_country_exp_prompt_v2_{str(uuid.uuid4())[:4]}"
exp_prompt_v2_template = "You are a helpful geography expert. The user will provide a city name: {{city_name}}. Your task is to respond with ONLY the name of the country where this city is located. Do not add any extra words or punctuation."
exp_prompt_v2_params = CompletionCreateParamsBase(
model="gpt-3.5-turbo",
temperature=0.0,
messages=[
{"role": "system", "content": "You are a precise geography expert."},
{"role": "user", "content": exp_prompt_v2_template}
],
)
try:
prompt_v2_obj = PromptVersion.from_openai(exp_prompt_v2_params)
exp_prompt_v2_phoenix = client.prompts.create(
name=exp_prompt_v2_name, version=prompt_v2_obj,
prompt_description="V2: Detailed prompt with role-setting for city-to-country (gpt-3.5-turbo)"
)
logger.info(f"Experiment Prompt V2 ('{exp_prompt_v2_name}') created. Version ID: {exp_prompt_v2_phoenix.id}")
except Exception as e:
logger.error(f"Error creating experiment prompt V2: {e}")
exp_prompt_v2_phoenix = None
# 获取之前创建的数据集
experiment_benchmark_dataset = client.get_dataset(name=dataset_registry_name)
定义任务函数和评估函数,这里为了方便,评估函数直接判断输出是否相等。(默认情况下,评估函数的函数名代表了指标的名称)
# 定义通用的任务函数 (Task Function)
def run_llm_with_phoenix_prompt(phoenix_prompt_obj: PromptVersion, dataset_input_row: dict):
city_variable_for_template = dataset_input_row.get("city_name_for_model")
if city_variable_for_template is None:
raise ValueError("Dataset row is missing the 'city_name_for_model' input key.")
formatted_api_call_payload = phoenix_prompt_obj.format(variables={"city_name": city_variable_for_template})
api_params = {
"model": formatted_api_call_payload.get("model"),
"messages": formatted_api_call_payload.get("messages"),
"temperature": formatted_api_call_payload.get("temperature"),
}
if not api_params["messages"]:
raise ValueError(f"Formatted prompt (ID: {phoenix_prompt_obj.id}) did not produce messages.")
oai_client = OpenAI(api_key=openai.api_key, base_url=openai.api_base)
response = oai_client.chat.completions.create(**api_params)
return response.choices[0].message.content.strip()
# 定义通用的评估函数 (Evaluator Function)
def check_country_match(output: str, expected: dict):
return output.lower() == expected.get("correct_country_answer", "").lower()
最后,我们分别为两个不同版本的 Prompt 运行实验。functools.partial 用于将固定的 Prompt 对象绑定到任务函数上。
logger.info(f"Running experiment for Prompt V1 (ID: {exp_prompt_v1_phoenix.id})...")
try:
task_for_v1 = functools.partial(run_llm_with_phoenix_prompt, exp_prompt_v1_phoenix)
experiment_results_v1 = run_experiment(
dataset=experiment_benchmark_dataset,
task=task_for_v1,
evaluators=[check_country_match],
experiment_name=f"CityCountry_PromptV1_Test_{str(uuid.uuid4())[:4]}",
experiment_description="Testing concise prompt (V1) for city-to-country mapping.",
experiment_metadata={"prompt_version_id": exp_prompt_v1_phoenix.id, "model_used": exp_prompt_v1_phoenix._model_name}
)
logger.info("Experiment for Prompt V1 completed.")
except Exception as e:
logger.error(f"Error running experiment for Prompt V1: {e}")
# 运行实验 - 针对 Prompt V2
logger.info(f"Running experiment for Prompt V2 (ID: {exp_prompt_v2_phoenix.id})...")
try:
task_for_v2 = functools.partial(run_llm_with_phoenix_prompt, exp_prompt_v2_phoenix)
experiment_results_v2 = run_experiment(
dataset=experiment_benchmark_dataset,
task=task_for_v2,
evaluators=[check_country_match],
experiment_name=f"CityCountry_PromptV2_Test_{str(uuid.uuid4())[:4]}",
experiment_description="Testing detailed prompt (V2) with role-setting for city-to-country.",
experiment_metadata={"prompt_version_id": exp_prompt_v2_phoenix.id, "model_used": exp_prompt_v2_phoenix._model_name}
)
logger.info("Experiment for Prompt V2 completed.")
except Exception as e:
logger.error(f"Error running experiment for Prompt V2: {e}")
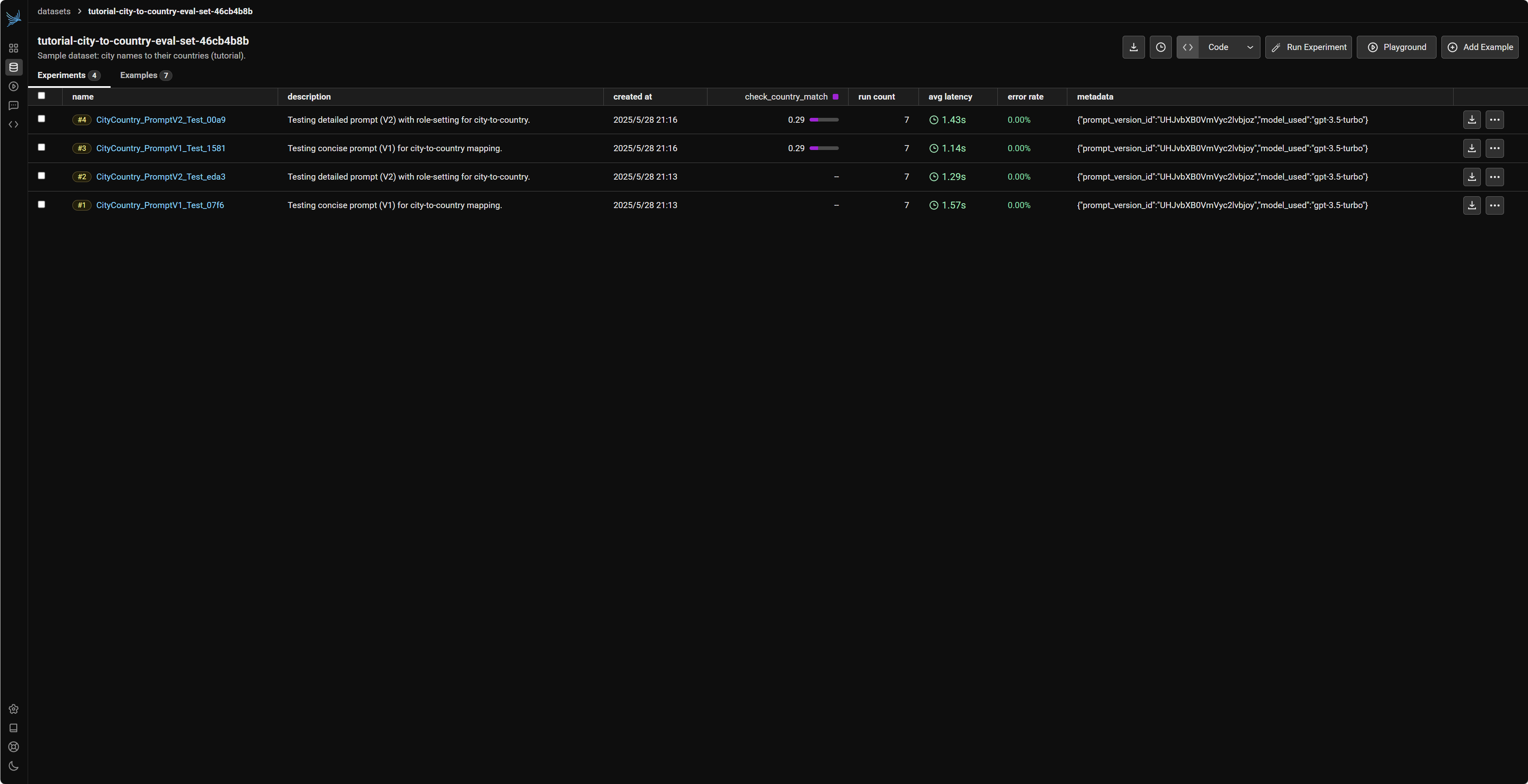
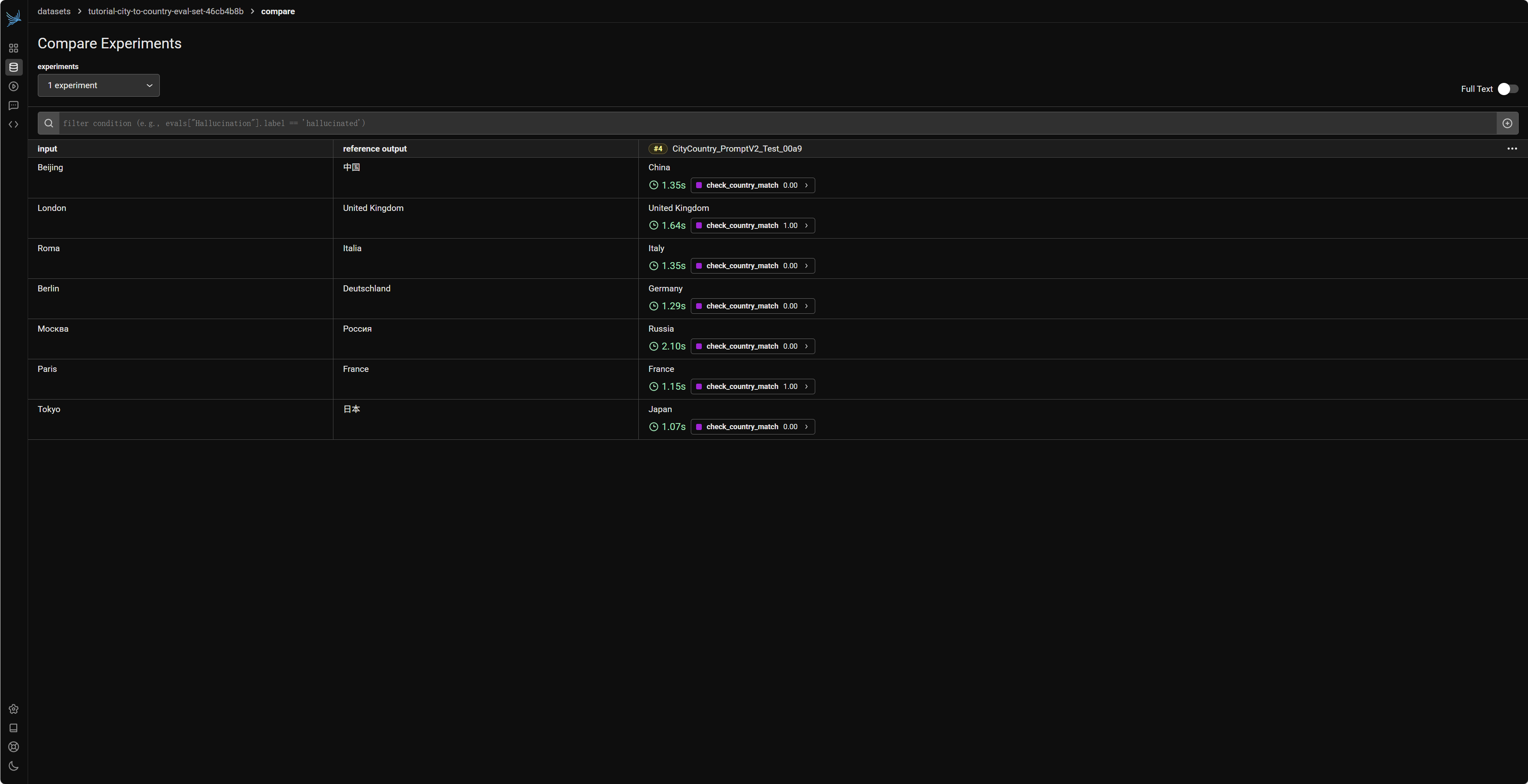
在 Phoenix UI 中,您可以进入对应的数据集 (tutorial-city-to-country-eval-set-...),然后在其 "Experiments" 标签页下找到这两个(或更多)实验。Phoenix 提供了比较不同实验结果的功能,让您可以直观地看到哪个 Prompt 版本在 check_country_match 这个评估指标上表现更好,从而做出数据驱动的决策来优化您的 LLM 应用。
总结与后续展望
在本篇文章(LLMOps 入门系列第二篇)中,我们以 Arize Phoenix 为核心工具,系统性地演练了其在大型语言模型(LLM)应用开发与运维中的关键功能。我们从 Phoenix 的环境初始化入手,详细介绍了如何利用其强大的追踪能力来观测不同框架(OpenAI, LangChain, LlamaIndex, Langgraph)下的 LLM 调用,以及如何管理和追踪多轮会话。随后,我们探讨了 Phoenix 在 Prompt 管理、Dataset 构建与管理、以及如何进行 LLM 输出评估(如幻觉检测、问答正确性)。最后,我们还简要介绍了该工具在实验驱动优化方面提供的便捷工具和流程。
通过这些实践,我们希望您能体会到 Phoenix 作为一个轻量级且功能全面的 LLMOps 工具,是如何帮助开发者提升 LLM 应用的可观测性、加速迭代优化,并最终构建更可靠、更高质量的 AI 产品。
展望未来,本系列将继续以 Phoenix 为核心,深入探讨 LLMOps 在更具体场景下的应用:
- 第三篇:基于 Phoenix 的高级 Prompt 工程与迭代。我们将聚焦于如何利用 Phoenix 的追踪、评估和实验功能,系统性地进行 Prompt 设计、测试、版本控制和优化,以提升模型在特定任务上的表现。
- 第四篇:深入剖析 Agent 执行:工具调用与决策链路的可观测性。我们将探讨如何使用 Phoenix 来追踪和分析 Agent(例如基于 Langgraph 构建的 Agent)的复杂执行流程,特别是其工具(Tool)调用和内部决策逻辑,以便更好地调试和优化 Agent 行为。
- 第五篇:RAG 系统全链路诊断与性能提升实战。在前文对 RAG 概念性介绍的基础上,我们将更深入地探讨如何结合 Phoenix 的追踪和评估能力,对 RAG 系统的各个环节(检索质量、上下文相关性、生成内容的事实一致性等)进行全链路诊断,并探索提升 RAG 系统整体性能的策略。
我们希望通过这一系列由浅入深、理论与实践相结合的文章,能让大家对 LLMOps 的理解从概念层面真正走向动手操作,并最终能够运用所学知识提升自己 LLM 应用的质量和效率。
请持续关注我们的 LLMOps 系列文章,让我们一同深入探索大模型应用的落地与精益运营之道!