LLM 推理架构的存算分离革命:P/D 分离技术深度解析
- 物理本质异构:LLM 推理分为计算密集的预填充(Prefill)和访存密集的解码(Decode),两者对硬件的需求存在本质冲突。
- 根治干扰:P/D 分离通过物理/进程隔离,彻底解决了长文本预填充抢占解码资源导致的“队头阻塞”与延迟抖动。
- 资源最优配比:允许根据业务负载动态调整 P:D 节点比例,最高可提升 4.48 倍的有效吞吐量(Goodput)。
- 工业基石:vLLM V1 架构已深度集成该技术,DeepSeek、Moonshot 等顶尖厂商已将其作为超长上下文服务的底层标准。

本文深度解析 LLM 的 P/D 分离架构。结合 vLLM 与 DeepSeek 的工程实践,阐述该架构如何通过物理隔离打破显存瓶颈,在保障确定性 SLO 的前提下,实现有效吞吐量 (Goodput) 的最大化。
在大规模语言模型(LLM)从实验室原型向生产环境迁移的过程中,推理效率、系统稳定性与服务等级协议(SLO, Service Level Objective)的达成能力,已成为衡量底层基础设施优劣的核心指标。随着模型参数量迈入万亿门槛(如 DeepSeek-V3, GPT-4 等),传统的单体化、耦合式推理架构在应对极高并发与超长上下文请求时,逐渐暴露出计算与显存资源利用率失衡以及延迟抖动难以控制的结构性瓶颈。
预填充与解码分离(Prefill-Decode Separation,简称 P/D 分离,亦称 Disaggregated Inference) 作为一种革命性的系统优化范式,通过在物理或逻辑层面解耦模型推理的两个异质阶段,为大模型服务的高效扩展提供了坚实的理论支撑与工程路径。
%%{init: {
'theme': 'base',
'themeVariables': {
'primaryColor': '#007bff',
'edgeLabelBackground': '#ffffff',
'tertiaryColor': '#f8f9fa',
'fontFamily': 'arial'
}
}}%%
graph TD
%% --- 0. 全局设置 (修复点:在此处定义曲线样式) ---
linkStyle default interpolate basis
%% --- 1. 样式定义 (Class Definitions) ---
classDef user fill:#6c757d,stroke:#495057,stroke-width:2px,color:#fff,rx:5,ry:5;
classDef router fill:#6f42c1,stroke:#563d7c,stroke-width:3px,color:#fff,rx:10,ry:10,shadow:5px;
classDef prefill fill:#0056b3,stroke:#004494,stroke-width:2px,color:#fff,rx:5,ry:5;
classDef decode fill:#00897b,stroke:#00695c,stroke-width:2px,color:#fff,rx:5,ry:5;
classDef storage fill:#ffc107,stroke:#d39e00,stroke-width:2px,stroke-dasharray: 5 5,color:#212529,rx:5,ry:5;
classDef network fill:#fd7e14,stroke:#e65c00,stroke-width:2px,color:#fff,shape:hexagon;
classDef note fill:#e9ecef,stroke:none,color:#495057,font-size:12px;
classDef transparent fill:none,stroke:none,color:#212529,font-weight:bold;
%% --- 2. 节点布局 ---
%% 顶层
User(("👤 用户 / Client
User Request")):::user
Router{{⚡ 全局路由
Global Router}}:::router
%% 中层:计算集群
subgraph Compute_Layer [ ]
direction LR
%% 左侧:预训练
subgraph Prefill_Cluster ["📦 预填充集群 (Prefill)"]
direction TB
P_Node1["P-Node 1
Compute-bound"]:::prefill
P_Note[/"📝 任务: 生成 KV Cache
首 Token 延迟 (TTFT) 敏感"/]:::note
end
%% 右侧:解码
subgraph Decode_Cluster ["🚀 解码集群 (Decode)"]
direction TB
D_Node1["D-Node 1
Memory-bound"]:::decode
D_Note[/"📝 任务: 逐字生成
吞吐量 (TPOT) 敏感"/]:::note
end
end
%% 底层:数据枢纽
subgraph Transfer_Layer ["🔗 KV Cache 传输枢纽"]
direction TB
Network{{📶 高速互联网络
RoCE / IB / NVLink}}:::network
SharedStorage[("💾 分离式存储
Mooncake / 3FS")]:::storage
end
%% --- 3. 连线逻辑 ---
%% Group A: 控制流 (蓝色实线)
%% 索引: 0, 1, 2, 3
User == "(1) 发起请求" ==> Router
Router == "(2) 调度 Prefill" ==> P_Node1
Router -. "(5) 唤醒 Decode" ..-> D_Node1
D_Node1 == "(6) 流式返回" ==> User
%% Group B: 数据流 (橙色虚线)
%% 索引: 4, 5, 6, 7
P_Node1 -- "(3) 写入 KV" --> Network
Network -.->|"(4a) P2P 直传"| D_Node1
Network -.->|"(4b) 异步持久化"| SharedStorage
SharedStorage -.->|"(4c) 缓存未命中回拉"| D_Node1
%% --- 4. 样式应用 ---
%% 0-3 是控制流 (蓝色)
linkStyle 0,1,2,3 stroke:#0d6efd,stroke-width:3px,fill:none;
%% 4-7 是数据流 (橙色, 虚线)
linkStyle 4,5,6,7 stroke:#fd7e14,stroke-width:3px,stroke-dasharray: 5 5,fill:none;
%% --- 5. 布局微调 ---
P_Node1 ~~~ D_Node1
class Compute_Layer,Transfer_Layer transparent一、P/D 分离架构的起源与核心价值
1.1 概念诞生背景
P/D 分离概念的出现,标志着 LLM 推理服务从“追求峰值吞吐(Throughput)”向“追求确定性服务质量(Deterministic SLO)”的范式转型。随着企业级应用对实时交互要求的提升,单一的每秒请求数(RPS)已不足以衡量真实的用户体验。
业界为此引入了 “有效吞吐量”(Goodput) 的概念。与传统吞吐量不同,Goodput 特指在满足严格的首 Token 延迟(TTFT)和 Token 间延迟(TPOT)约束下的最大有效请求速率。
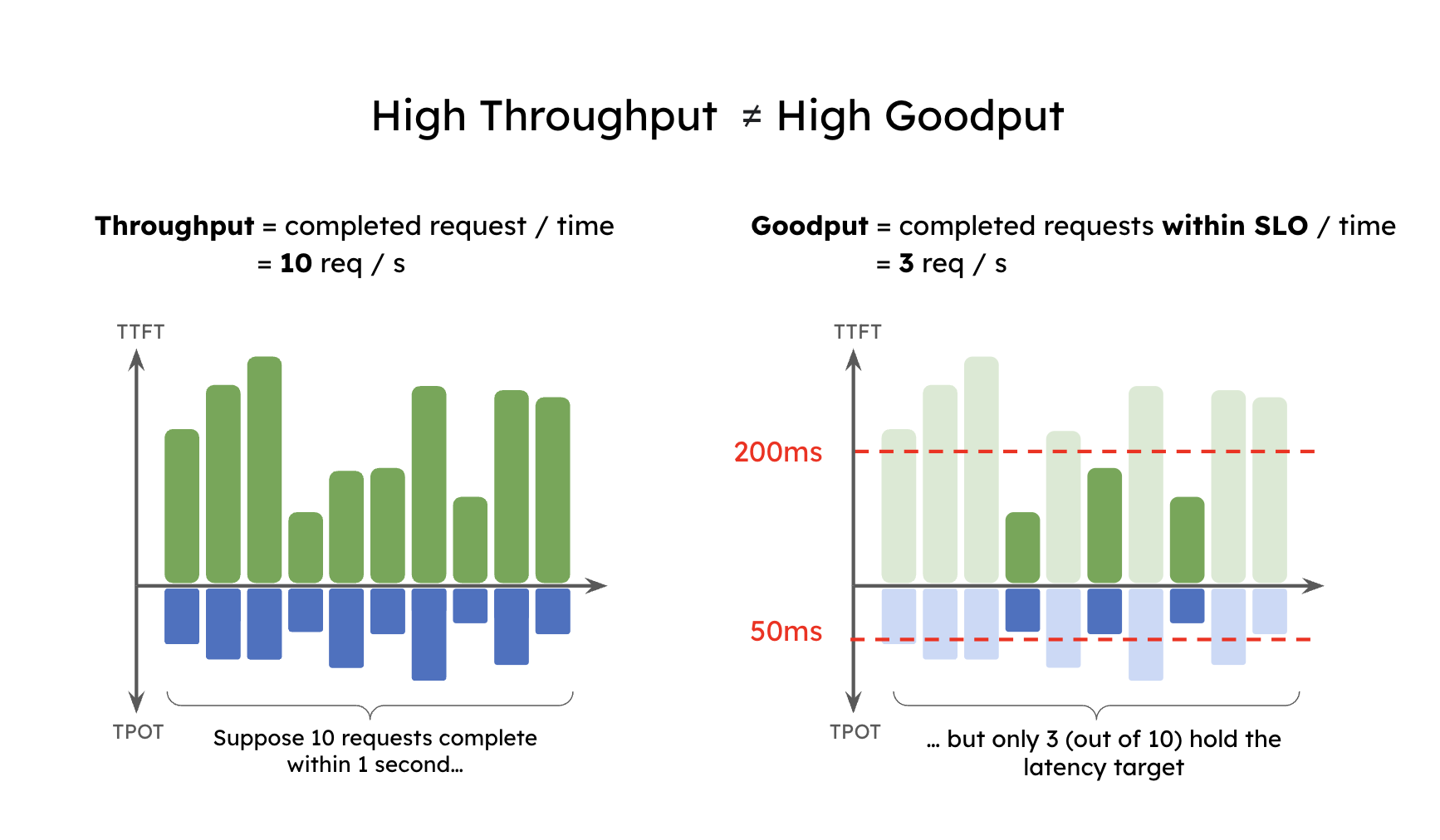
早期的原型系统(如 DistServe)研究发现,在传统的耦合架构中,预填充(Prefill)阶段的突发计算会严重争抢解码(Decode)阶段的资源。通过物理隔离这两个集群,可以彻底消除阶段间的资源竞争。解耦后的系统被证明可以在保持高并发的同时,将 TPOT 的稳定性提升数倍。这一架构创新的核心,在于将 LLM 推理转化为一条分布式流水线:
- 预填充节点:类似于“零部件加工中心”,负责处理 Prompt 并生成 KV Cache(计算密集型);
- 解码节点:类似于“总装车间”,负责利用 KV Cache 逐字生成回复(访存密集型);
- 高速互联:作为流转 KV Cache 这一“中间件”的传送带。
1.2 解决的核心挑战
P/D 分离架构的设计初衷,是为了从根本上解决单体架构无法调和的三个关键矛盾:
- 保障确定性的低延迟。在代码补全、实时语音翻译等对节奏感要求极高的场景中,任何延迟抖动都是不可接受的。物理隔离确保了解码节点不再受突发长文本预填充请求(Long-context Prefill)的干扰,从而保证了 Token 生成的平滑度。
- 实现异构资源的精准配比。预填充和解码对硬件资源的需求截然不同。P/D 分离允许系统管理员根据实际业务负载(例如 Prompt 平均长度与生成长度的比例)灵活调整两类节点的比例(P:D Ratio)。
- 长文本摘要场景:增加预填充节点,以应对海量输入的计算压力;
- 创意写作场景:增加解码节点,以满足长文本生成的显存带宽需求。
- 分阶段的并行策略优化。解耦后,不同阶段可以采用最适合其计算特征的并行策略:
- 预填充集群:倾向于采用张量并行(Tensor Parallelism, TP),利用多卡算力并行计算,极致压缩 TTFT;
- 解码集群:倾向于采用数据并行(Data Parallelism, DP)或专家并行(Expert Parallelism, EP),以支持数千个并发流,在显存带宽受限的前提下最大化系统吞吐。
二、大模型推理的物理特质与资源悖论
2.1 预填充与解码阶段的异质性分析
大语言模型(LLM)的自回归推理过程并非同质的计算流,而是由两个在算术强度和硬件瓶颈上截然不同的阶段组成:预填充阶段(Prefill)与解码阶段(Decode)。理解这种异质性是 P/D 分离架构建立的物理基础。
预填充阶段是模型处理输入提示词(Prompt)并生成第一个输出 Token 的过程。 在这一阶段,模型利用 Transformer 的自注意力机制并行计算输入序列中所有 Token 之间的相互关系。从计算特征上看,预填充涉及大规模矩阵乘法运算(GEMM),其计算复杂度随序列长度呈二次方增长。由于该阶段能够充分激活 GPU 的张量核心(Tensor Cores),且数据重用率高,因此表现为典型的计算受限(Compute-bound) 模式。
解码阶段则是逐个 Token 生成的循环过程。 每一步生成都需要依赖前文生成的 Token 以及预填充阶段产生的 KV Cache。尽管单步生成的计算量远小于预填充阶段,但由于每一步都需要从显存中加载数百 GB 的模型权重以及不断增长的 KV Cache 张量,该阶段表现为典型的访存受限(Memory-bound) 模式。解码阶段的效率瓶颈在于显存带宽,而非计算峰值算力。

下表详细对比了这两个阶段在硬件层面的性能特征:
| 特征维度 | 预填充阶段 (Prefill) | 解码阶段 (Decode) |
|---|---|---|
| 计算模式 | 高度并行化的大规模矩阵乘法 | 序列化、低并行度的逐字生成 |
| 硬件瓶颈 | 算力受限 (Compute-bound) | 显存带宽受限 (Memory-bound) |
| 性能指标 | 首 Token 延迟 (TTFT) | Token 间延迟 (TPOT / ITL / TBT) |
| KV Cache 操作 | 计算、构建并写入缓存 | 读取旧缓存、更新并追加新缓存 |
| 并行策略偏好 | 宽张量并行 (TP) 以降低延迟 | 高数据并行 (DP) / 专家并行 (EP) 以提升吞吐 |
| 能耗特征 | 动态能耗为主,受算力频率影响大 | 静态泄露能耗显著,受执行时长主导 |
2.2 传统耦合架构的演进与局限
在 P/D 分离技术普及之前,工业界为解决显存与计算的冲突,经历了从静态批处理到分块预填充的技术演进,但始终未能根除资源耦合带来的核心矛盾。
2.2.1 静态批处理 (Static Batching)
这是早期推理引擎采用的最基础策略。系统在处理请求时遵循“全进全出”原则:
- 同步等待:系统初始化一个空批次,等待并填充请求直至达到预设大小。
- 锁定执行:批次一旦开始执行,所有请求(无论长短)必须同步进行预填充和解码。
- 队头阻塞:即使短请求已经完成生成,也必须等待批次中最长的请求完成后,显存资源才能被释放。

这种策略导致了严重的队头阻塞(Head-of-Line Blocking)效应,请求的 TTFT 极不稳定,且显存利用率因长短请求不均而出现大量碎片。
2.2.2 连续批处理 (Continuous Batching)
为了解决静态批处理的等待问题,Orca 和 vLLM 等系统引入了连续批处理(亦称迭代级调度)。该策略允许新请求在当前批次完成一次迭代后立即插入。

虽然这消除了显存碎片,但在混合部署模式下引入了新的干扰问题: 当一个新的长 Prompt 请求被插入队列时,GPU 必须暂停当前的解码任务,转而全力执行新请求的预填充。由于预填充会占满计算单元,正在进行的解码流会出现明显的卡顿。
2.2.3 分块预填充 (Chunked Prefill)
分块预填充是 P/D 分离成熟前的主流缓解方案。系统不再一次性处理完整个 Prompt,而是将其拆分为多个较小的块(Chunk,例如 512 tokens)。在每个迭代步中,GPU 既处理一个预填充块,也处理若干解码任务。
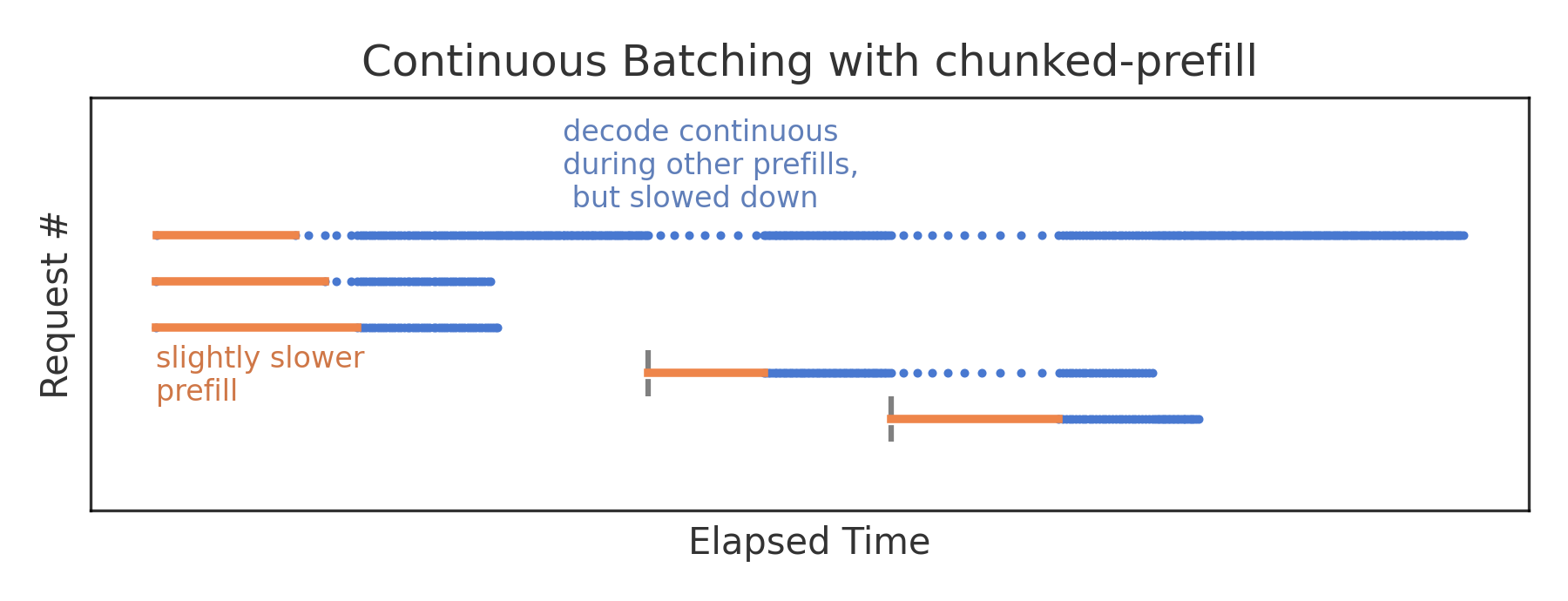
虽然分块预填充通过“化整为零”平滑了延迟抖动,但它本质上是一种妥协:
- 计算开销增加:分块导致 Attention 计算无法充分利用算子融合优势,增加了总计算量。
- 资源仍未解耦:预填充块与解码任务仍在同一张 GPU 上争抢显存带宽和 L2 Cache。
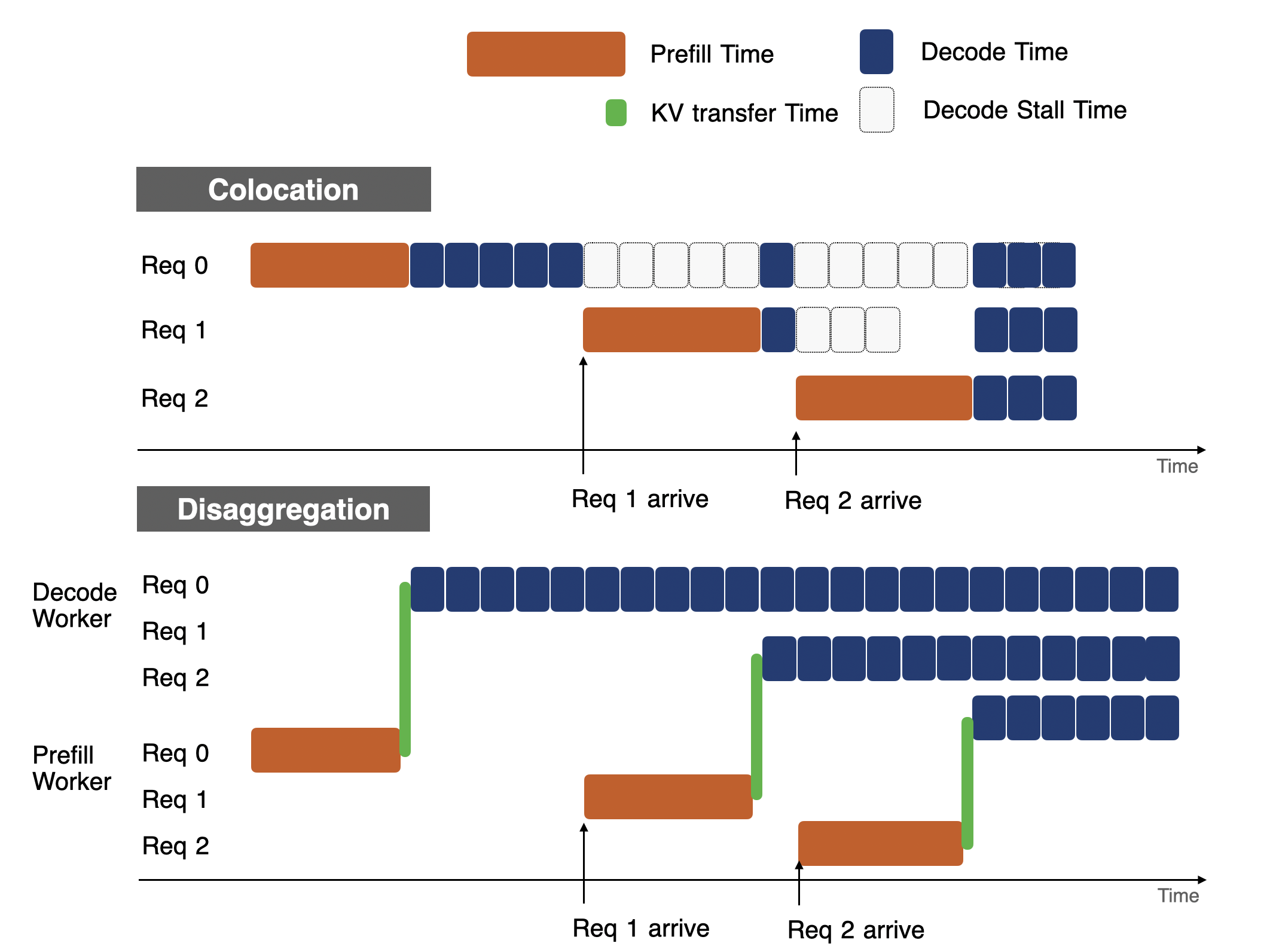
2.2.4 P/D 分离的决定性优势
相比于分块预填充的软件级调度,P/D 分离实现了物理级的资源隔离。实验数据显示,在处理长文本摘要任务时,采用 P/D 分离架构的系统比传统架构提升了 4.48 倍的有效吞吐量(Goodput),并将 SLO 违规率降低了 10 倍以上 (详情见此链接)。这证明了在大规模生产环境中,物理隔离带来的性能增益远大于网络传输引入的通信成本。
三、P/D 分离的架构实现与关键技术
3.1 总体架构流转过程
实现 P/D 分离的典型系统架构通常包含三个核心组件:全局路由层、预填充计算池和解码计算池。一个标准的请求生命周期如下:
- 请求分发 (Global Routing):全局路由根据后端节点的实时负载、显存水位以及预期的 SLO 目标,将用户请求指派给某个预填充节点。
- 预填充计算 :预填充节点接收 Prompt,执行完整的模型前向传播,生成首个输出 Token,并在此过程中计算出完整的 Key-Value (KV) Cache。
- 状态迁移:这是 P/D 分离的关键路径。预填充节点通过高速网络将 KV Cache 传输至指定的解码节点。
- 增量解码 (Speculative Decode):解码节点接收到缓存后,直接将其加载至本地显存(或通过 Zero-Copy 技术读取),在此基础上开始自回归生成,直到满足停止条件。

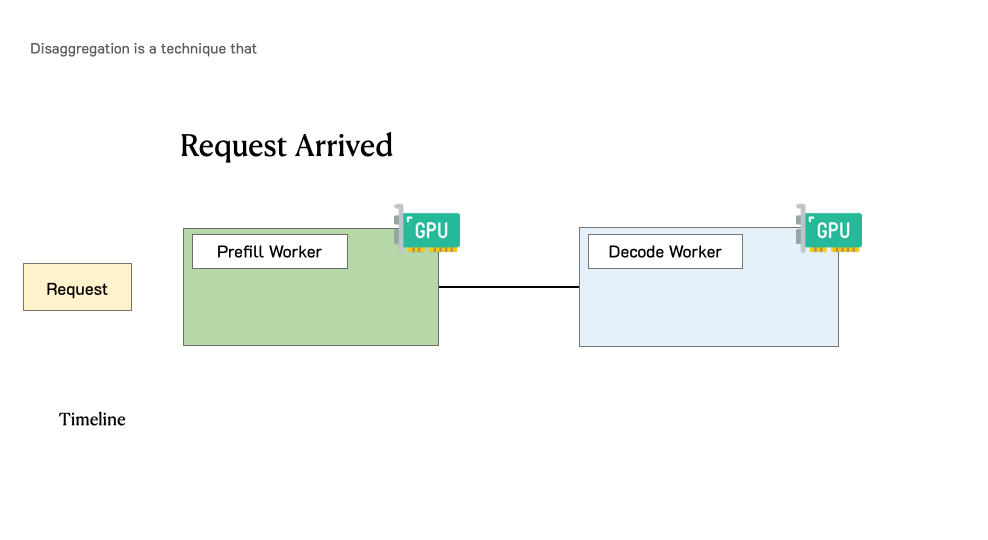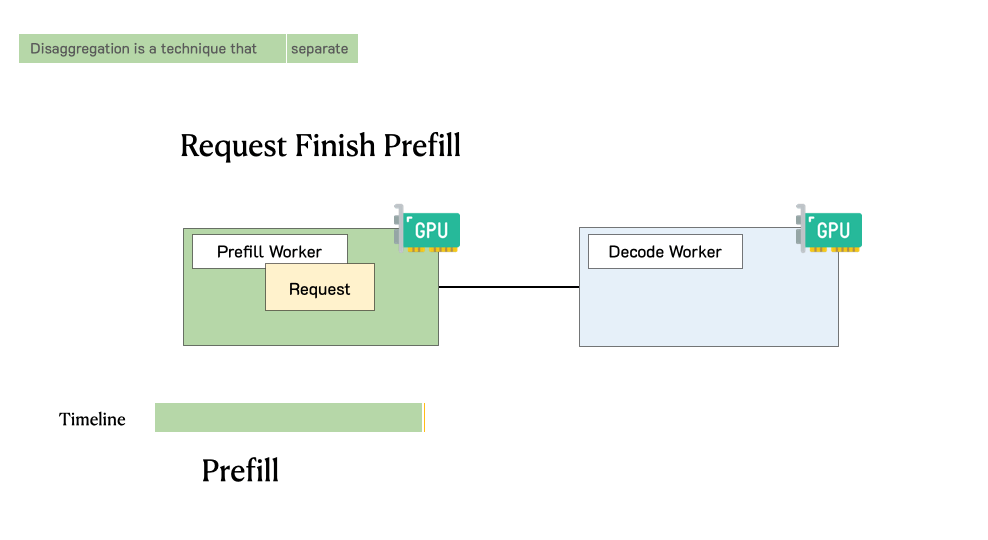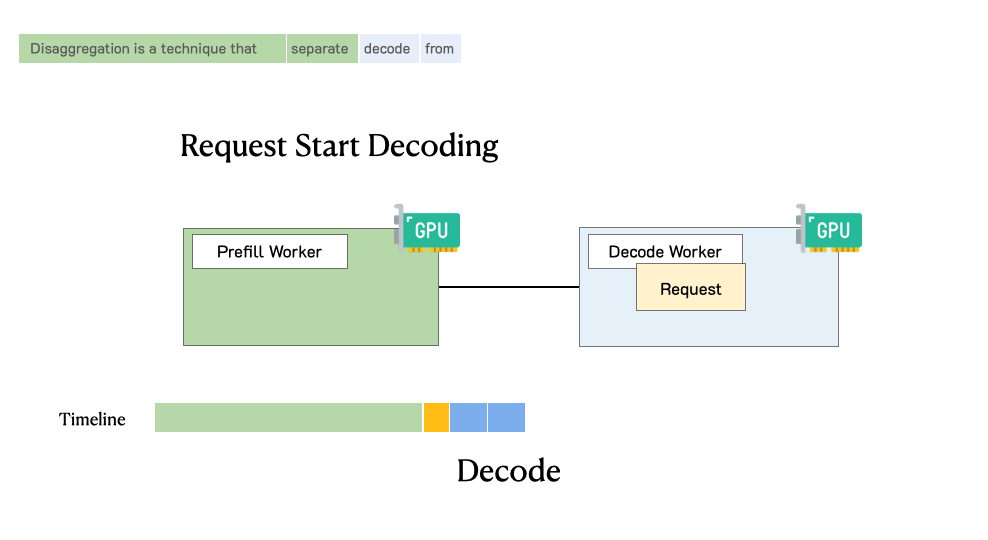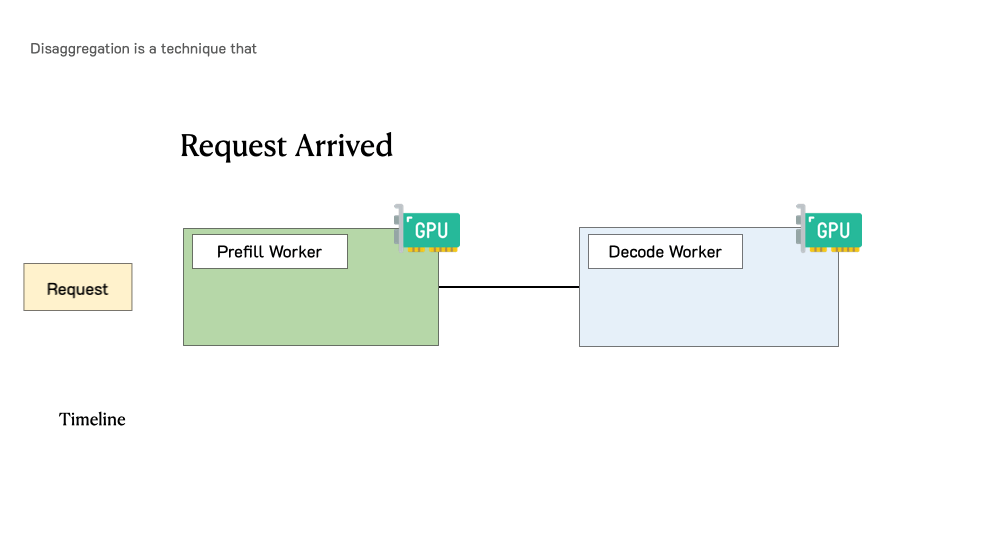
3.2 KV Cache 的传输与存储机制
KV Cache 的高效流转是 P/D 分离架构的“生命线”。由于长上下文的 KV 张量体积巨大(单请求可能达数 GB),网络带宽和显存 IO 往往成为制约 TTFT 的关键因素。业界目前主要存在三种存储与传输范式:
- P2P 直接传输:以 vLLM 的
NixlConnector为代表。预填充节点计算完成后,通过 RDMA 或 NVLink 直接将数据“推”送到解码节点的显存中。- 优势:延迟最低,点对点传输效率高。
- 劣势:难以复用缓存,节点间耦合度较高。
- 分布式全局存储:以 Moonshot AI 的 Mooncake 架构为代表。系统引入一个逻辑上统一的 KV Cache 存储池(由 CPU 内存、SSD 或专用显存组成)。预填充节点将数据写入池中,解码节点按需读取。
- 优势:彻底解耦,支持复杂调度(如 Context Caching),易于实现多级缓存。
- 劣势:对存储系统的吞吐能力要求极高。
- 分层存储与卸载:如 LMCache,它支持将 KV Cache 卸载至本地 CPU 内存或远程 Redis/Database。这种机制主要解决 GPU 显存容量瓶颈,使单节点能处理的并发上下文长度成倍增加。
下表对比了不同传输介质在 P/D 分离架构中的应用场景:
| 传输技术 | 典型带宽 | 适用场景 | 核心优势 |
|---|---|---|---|
| NVLink | 900 GB/s+ | 节点内 | 极低延迟,适合单机多卡间的 P/D 分离 |
| InfiniBand / RoCE | 200 - 400 Gbps | 跨节点 | 绕过 CPU 内核协议栈,支持 RDMA 零拷贝传输 |
| TCP/IP (Ethernet) | 10 - 100 Gbps | 通用网络 | 兼容性好,但序列化开销大,仅适用于低负载或实验环境 |
| 3FS (Distributed FS) | TiB/s 级集群总带宽 | 集群级存储 | 支持海量 KV Cache 的持久化与共享,解决显存溢出问题 |
四、工业级实现:深入 vLLM 引擎的 P/D 分离机制
作为目前高性能大模型推理领域的行业标准,vLLM 在其最新的 V1 版本架构中,对 P/D 分离(官方命名为 Disaggregated Prefilling)进行了内核级的深度集成。本章将以 vLLM 为解剖对象,具体分析 P/D 分离如何在工程代码层面落地。
4.1 vLLM V1 引擎的设计哲学
vLLM V1 对 P/D 分离的实现遵循“非侵入式”设计原则。其核心目标是让用户无需修改模型代码,仅通过配置即可将单体 vLLM 实例动态转化为预填充实例(KV Producer)或解码实例(KV Consumer)。
这一机制的核心载体是 KVConnector 接口。该接口屏蔽了底层传输细节,使得上层调度器(Scheduler)可以像操作本地显存一样操作远程 KV Cache。这种设计成功解决了“计算与传输重叠(Compute-Communication Overlap)”的难题,确保数据搬运不会阻塞 GPU 的计算流。
4.2 核心组件与抽象层
vLLM 内部通过三层抽象构建了跨实例的 KV Cache 协同机制:
- 连接器 (Connector) —— 逻辑桥梁:这是连接生产者与消费者的顶层接口。vLLM 提供了多种后端实现以适配不同环境:
NIXLConnector:基于 PyTorch TensorPipe,适用于点对点传输。SharedStorageConnector:适用于基于共享文件系统(如 NFS/3FS)或内存池(如 Mooncake)的场景。LMCacheConnector:专为多级缓存卸载设计的连接器。
- 查找缓冲区 (LookupBuffer) —— 元数据索引:其行为类似于一个分布式的“哈希索引表”。
- 写入侧:当预填充节点完成计算,会将 KV 张量的物理地址与其对应的 Token ID 哈希值存入缓冲区。
- 读取侧:解码节点在调度前,通过
insert和drop_select等类 SQL 原语查询该缓冲区,确认所需 KV Cache 是否就绪。这确保了调度器不会向数据未就绪的节点分发请求。
- 传输管道 (Pipe) —— 数据高速公路:这是一个底层的单向 FIFO 数据通道,负责实际的张量字节流传输。在高性能配置下,Pipe 通常基于 NCCL 库或异步 Socket 实现,以保证张量传输的顺序性与完整性。

4.3 调度逻辑:控制面与数据面的协同
vLLM 的 P/D 分离不仅仅是数据搬运,更是一场精密的分布式调度。其执行流程被严格划分为控制平面(调度器)和数据平面(Worker 进程):
4.3.1 控制平面:调度器连接器 (Scheduler Connector)
运行在 CPU 主进程中,负责“指挥”。
- 当调度器从等待队列中提取请求时,首先查询全局
LookupBuffer。 - 利用前缀缓存(Prefix Caching)机制,检查远程节点是否已存在该请求的部分 KV Cache。
- 生成包含“传输指令”的元数据(Metadata),指示 Worker 何时、向何处发送或拉取数据。
4.3.2 数据平面:工作进程连接器 (Worker Connector)
运行在 GPU 关联的执行进程中,负责“搬砖”。
- 发送端 (Producer):在模型前向传播结束后,异步调用
save_kv_layer。该操作与下一层网络的计算并行执行,通过流水线掩盖传输延迟。 - 接收端 (Consumer):调用
start_load_kv触发远程拉取。为了极致性能,vLLM 支持在解码当前 Token 的同时,预取下一个请求所需的 KV Cache(即 Prefetching)。
4.4 配置与部署实践
启用 P/D 分离主要通过 --kv-transfer-config 参数实现,该参数接受 JSON 格式的配置字符串。
以下是一个典型的 1P1D (1 Prefill Node, 1 Decode Node) 部署范例:
# 启动解码节点
vllm serve meta-llama/Llama-3.1-8B \
--port 8001 \
--kv-transfer-config '{"kv_connector":"NIXLConnector", "kv_role":"kv_consumer", "kv_rank":1}'
# 启动预填充节点
vllm serve meta-llama/Llama-3.1-8B \
--port 8000 \
--kv-transfer-config '{"kv_connector":"NIXLConnector", "kv_role":"kv_producer", "kv_rank":0}'
在超大规模集群中,单纯的点对点传输可能导致网络拥塞。此时可结合 --kv-offloading-backend 参数,利用 Mooncake 或 3FS 作为中间存储介质。这种架构允许预填充节点将“冷”数据的 KV Cache 卸载到廉价的 SSD 池中,解码节点仅在需要时按需回拉,从而在有限的 H100/A100 显存中支持海量并发对话。
五、关键应用场景与工业级案例分析
P/D 分离架构并非单纯的理论模型,它已成为头部 AI 企业解决大规模服务瓶颈的“杀手锏”。以下是该架构在不同业务场景中的落地实践。
5.1 超长上下文交互 (Long-Context Understanding)
长文本处理是 P/D 分离最典型的受益场景。当用户上传一份数十万 Token 的财报或法律文档并提问时,单次预填充的计算耗时可能长达数秒。在传统架构中,这会导致同一 GPU 上的短对话用户遭遇严重的阻塞。
Kimi 智能助手以支持超长上下文(200k+ Tokens)著称。其底层架构利用 Mooncake 分离式推理系统,将预填充节点与解码节点完全解耦:
- 实现效果:通过将计算密集的 Prefill 任务调度至高算力集群,Kimi 在 NVIDIA A800/H800 集群上实现了 115% 至 107% 的容量提升(参考官方论文)。更重要的是,它保证了长文档处理任务不会干扰普通用户的即时聊天体验,实现了服务质量(SLO)的帕累托优化。
6.2 Agentic 工作流与多轮对话
在智能体(AI Agent)应用中,模型往往需要执行“思考-调用工具-再思考”(ReAct)的复杂循环。每一轮推理都会产生新的 KV Cache,但大部分历史上下文是重复的。
- 技术收益:缓存重用 。P/D 分离架构天然契合前缀缓存(Prefix Caching)技术。系统可以将中间状态的 KV Cache 持久化到全局共享存储中。当 Agent 发起下一轮请求时,解码节点无需等待预填充节点重新计算历史 Token,而是直接从共享存储池中“挂载”之前的状态。这不仅大幅降低了 TTFT,也显著减少了重复计算带来的算力浪费。
6.3 异构硬件混合部署
P/D 分离为优化总拥有成本提供了全新的思路。由于预填充和解码对硬件的依赖不同,企业可以打破“同构集群”的限制。
DeepSeek-V3 的推理架构广泛采用了 P/D 分离策略:
- 预填充层: 部署最新的 NVIDIA H800 等高算力芯片,以快速吞噬海量 Token。
- 解码层: 部署显存容量大但算力相对较低的芯片(如 L40S 或上一代 A100),甚至可以利用国产算力芯片,以高性价比承载大规模并发生成。
- 存储层: 利用自研的 3FS (Fire-Flyer File System) 分布式存储,将成千上万块 NVMe SSD 聚合为超高带宽的共享存储池。这相当于为推理集群挂载了一个近乎无限的二级缓存池,极大地缓解了 GPU 显存的容量压力。
六、技术挑战与未来演进
6.1 当前面临的技术挑战
尽管 P/D 分离优势明显,但在工程落地中仍面临物理定律的制约,核心在于通信墙(Communication Wall)。
- 带宽瓶颈: 对于超大模型(如 Llama-3-405B)和超长序列,单个请求的 KV Cache 可能高达数 GB。在跨机柜传输时,即使是 400Gbps 的 InfiniBand 网络也可能引入数十毫秒的延迟。
- 应对方向:业界正在积极探索KV Cache 量化(如 FP8/Int4) 和稀疏化传输技术,试图在不损失精度的前提下将传输数据量压缩 50% 以上。
- 调度复杂性: 调度器需要根据网络拓扑(机架感知)、显存碎片率和节点实时负载,在微秒级时间内做出最优路由决策。这要求调度算法具备极高的预测准确性。
- 隐藏状态重算: 在 vLLM V1 的早期实现中,解码节点接收缓存后,有时需重算最后一个 Token 的隐藏状态(Hidden States)以启动采样。业界正在推动“全张量转移”(包括 Hidden States 转移),以消除解码端的任何冗余计算。
6.2 未来演进:EPD 架构与池化推理
随着多模态模型(LMM)的爆发,推理阶段正在从两阶段演变为三阶段,推动架构进一步演进。
- EPD 架构 (Encode-Prefill-Decode): 对于包含视频或高分辨率图像的输入,视觉编码(Encode)阶段的计算量甚至超过了文本预填充。前沿框架(如 SGLang)正在探索将编码阶段独立解耦,形成 Encode(视觉特征提取)- Prefill(文本处理)- Decode(文本生成) 的三阶段物理分离架构。
- 资源池化 (Pooled Inference): 未来的大模型推理将不再以“服务器”为单位,而是以“资源池”为单位。计算算力池、显存池、KV 存储池和网络路由池将通过软件定义(Software-Defined)的方式动态组装。在这种范式下,P/D 分离将沉淀为 AI 操作系统的内核级能力,实现真正的弹性伸缩。
总结
预填充与解码分离(P/D 分离)架构的兴起,是大模型推理技术迈向成熟与规模化的必然结果。它通过深刻洞察 Transformer 模型推理中阶段性的资源矛盾,利用分布式系统的方法论解决了计算与访存、延迟与吞吐之间的平衡难题。
从 vLLM 的 API 抽象到 Mooncake 的全局内存池,再到 DeepSeek 的海量 SSD 共享,P/D 分离正在从一种实验性技术演变为支撑全球顶级 AI 服务的基础设施。对于追求极致用户体验和低运营成本的企业而言,掌握并部署 P/D 分离架构已不再是可选项,而是通往 AGI 规模化应用的必经之路。
参考链接
- Prefill vs. Decode Bottlenecks: SRAM–Frequency Tradeoffs and the Memory-Bandwidth Ceiling - arXiv
- Understanding the Two Key Stages of LLM Inference: Prefill and Decode(Part-1) - Medium
- Prefill and Decode for Concurrent Requests - Optimizing LLM Performance - Hugging Face
- Inside Real-Time LLM Inference: From Prefill to Decode, Explained | by Dev Patel | Medium
- Disaggregated Inference: 18 Months Later | Hao AI Lab @ UCSD
- Prefill-Decode Aggregation or Disaggregation? Unifying Both for Goodput-Optimized LLM Serving - arXiv
- Throughput is Not All You Need: Maximizing Goodput in LLM Serving using Prefill-Decode Disaggregation - Hao AI Lab
- Understanding the Prefill-decode Disaggregation in LLM Inference Optimization - NADDOD
- Disaggregated Prefilling (experimental) - vLLM
- Separating Prefill and Decode in LLM Inference: Why Performance Depends on the P:D Ratio | by Shawn Chen | Jan, 2026 | Medium
- Disaggregated Inference at Scale with PyTorch & vLLM – PyTorch
- Prefill-decode disaggregation | LLM Inference Handbook - BentoML
- Example: Disaggregated prefill - LMCache
- LLM distributed inference and PD disaggregation on AMD Instinct GPUs
- Welcome to Mooncake — Mooncake
- Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving - ResearchGate
- [RFC]: Top-level CLI interface for KV cache offloading · Issue #26858 - GitHub
- KV Cache Offloading with Huggingface vLLM Backend - KServe
- deepseek-ai/3FS: A high-performance distributed file system designed to address the challenges of AI training and inference workloads. - GitHub
- Disaggregated prefilling (experimental) - vLLM
- Inside vLLM: Anatomy of a High-Throughput LLM Inference System ...
- Design and Implementation of vLLM PD Separation Architecture: In-Depth Analysis of Engine V1 Version - Oreate AI Blog
- Understanding vllm kv cache
- Inside vLLM's New KV Offloading Connector: Smarter Memory Transfer for Maximizing Inference Throughput
- How to get kv cache value from vllm
- Proactive Intra-GPU Disaggregation of Prefill and Decode in LLM Serving - arXiv
- 1P1D Disaggregation performance · Issue #11345 · vllm-project/vllm - GitHub
- Optimizing Inference with Parameter/Data (P/D) Separation in vLLM Framework | Wilson Wu
- PD Disaggregation in LLM Inference - Emergent Mind
- Prefill-Decode Disaggregated Architectures - Emergent Mind
- [RFC]: Optional Hidden States Transfer in
KVConnectorBase_V1to Eliminate Decoder Prefix-Prefill in P/D Disaggregation · Issue #31064 · vllm-project/vllm - GitHub