深入 vLLM:高吞吐量 LLM 推理系统剖析
在大模型应用爆发的今天,推理系统的性能直接决定了产品的落地成本与用户体验。vLLM 凭借其独创的 PagedAttention 机制,解决了显存碎片化这一顽疾,成为了高性能推理引擎的代名词。
本文原文出自 Aleksa Gordić 之手,他用“倒金字塔”的结构将复杂的系统拆解得非常清晰。作为一名 LLM 领域相关从业者,我在阅读时深受启发,因此决定将其翻译出来与大家分享。
希望这份译文能帮你更轻松地推开 vLLM 的大门。由于水平有限,若有疏漏之处,欢迎在评论区指正交流。
- 原文链接:Inside vLLM: Anatomy of a High-Throughput LLM Inference System - Aleksa Gordić
- 作者:Aleksa Gordić
- 日期:2025-8-29

本文深度剖析 vLLM 高吞吐量推理架构。首先揭示 PagedAttention 与连续批处理如何突破显存瓶颈;继而探讨分块预填充、推测解码等高级特性;随后详述从单 GPU 到分布式集群的扩展实现;最后分析延迟与吞吐量的权衡策略及基准测试方法。
本文将系统拆解现代高吞吐量大型语言模型(LLM)推理系统的核心组件与高级功能。我将重点剖析 vLLM [1] 的工作原理。
这是系列文章的第一篇。内容编排采用倒金字塔结构(由面到点),旨在帮助你建立准确的高层系统认知模型,以免一开始就陷入细枝末节而无法自拔。
后续文章将深入探讨具体的子系统。
本文分为五个部分:
- LLM 引擎与引擎核心 :vLLM 的基石(调度、分页注意力 PagedAttention、连续批处理等)。
- 高级功能:分块预填充(Chunked Prefill)、前缀缓存(Prefix Caching)、引导式解码(Guided Decoding)、推测式解码(Speculative Decoding)、P/D 分离(分离式预填充/解码)。
- 扩展性:从单 GPU 到多 GPU 执行。
- 服务层:分布式/并发 Web 服务框架。
- 基准测试与自动调优:测量延迟和吞吐量。
- 本文分析基于 commit 42172ad (2025 年 8 月 9 日)。
- 目标受众:任何对顶尖 LLM 引擎工作原理感兴趣的人,以及有兴趣为 vLLM、SGLang 等项目做贡献的人。
- 我将重点关注 V1 引擎。同时也研究了 V0(现已弃用),这对于理解项目的演变非常有价值,且许多概念仍然沿用。
- 第一部分关于“LLM 引擎/引擎核心”的内容可能会有点枯燥且信息密度大——但博客的其余部分会有大量的示例和图示来辅助理解。
LLM 引擎与引擎核心
LLM 引擎是 vLLM 的基本构建模块。它本身即可实现高吞吐量推理,但仅适用于离线场景。此时,你还无法通过网络对外提供 API 服务。
我们将使用以下离线推理代码片段作为贯穿本文的示例(改编自 basic.py)。
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
def main():
llm = LLM(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0")
outputs = llm.generate(prompts, sampling_params)
if __name__ == "__main__":
main()
- VLLM_USE_V1="1" # 使用 v1 引擎
- VLLM_ENABLE_V1_MULTIPROCESSING="0" # 单进程
此配置具备以下特点:
- 离线(没有 Web 或分布式系统脚手架的支持)。
- 同步(所有执行都发生在单个阻塞进程中)。
- 单 GPU(没有数据/张量/流水线/专家并行,DP/TP/PP/EP = 1)。
- 标准 Transformer [2](支持 Jamba 等混合模型需要更复杂的混合 KV 缓存显存分配器)
在此基础上,我们将逐步构建一个在线、异步、多 GPU、多节点的推理系统,但仍以标准 Transformer 为基础。
在这个例子中,我们主要做了两件事:
- 实例化一个引擎。
- 调用其
generate方法,根据给定的提示(Prompts)进行采样。
让我们从分析构造函数开始。
LLM 引擎构造函数
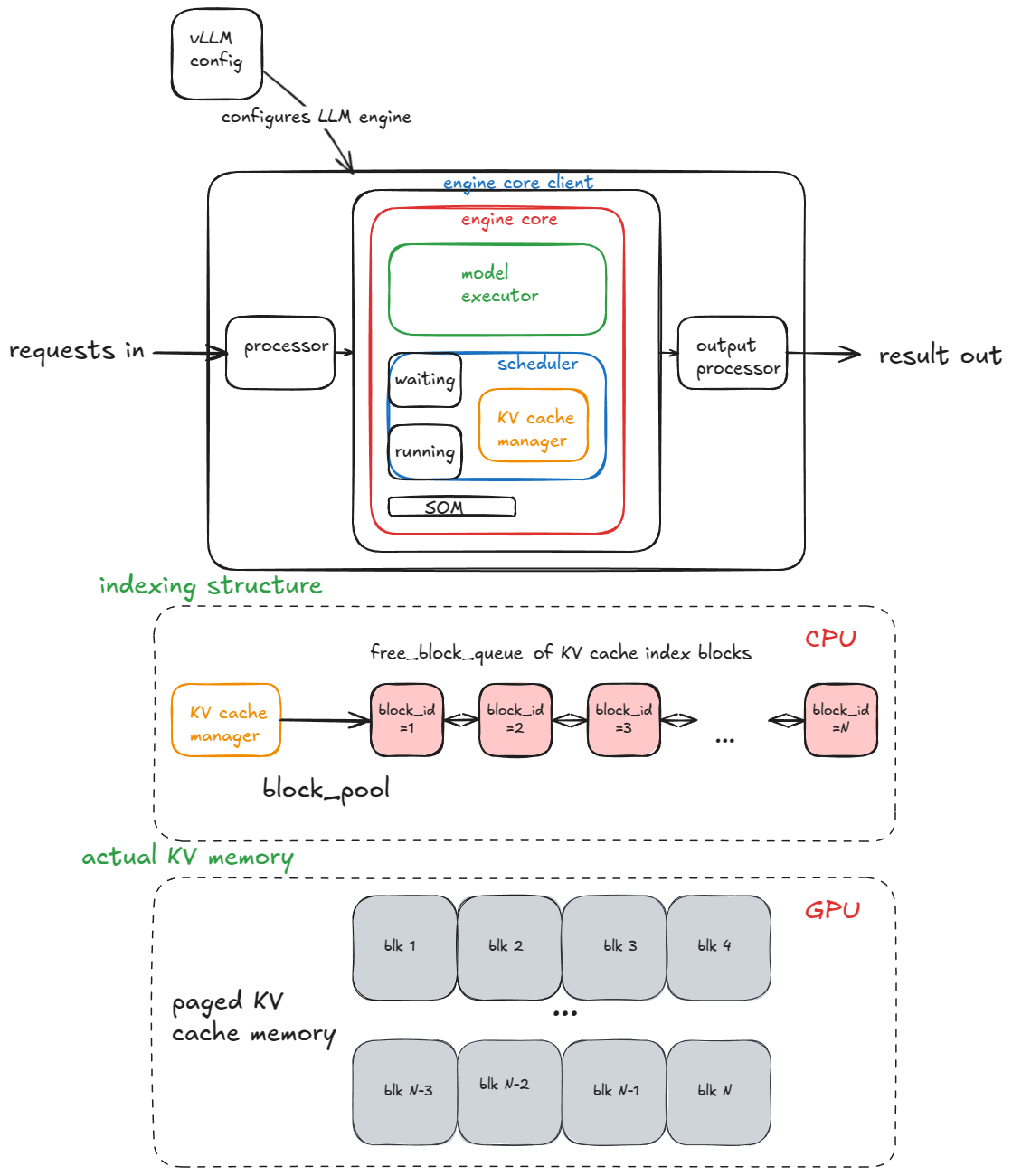
引擎的主要组件包括:
- vLLM 配置:包含所有用于配置模型、缓存、并行性等的开关与选项。
- 处理器:负责执行验证、分词与处理,将原始输入转换为
EngineCoreRequests。 - 引擎核心客户端:在示例中,我们使用
InprocClient(进程内客户端),它本质上等同于EngineCore;我们将逐步升级到DPLBAsyncMPClient,以支持大规模服务。 - 输出处理器:将原始的
EngineCoreOutputs转换为用户可见的RequestOutput。
随着 V0 引擎被弃用,类名和细节可能会发生变动。我将重点强调核心思想,而不是确切的函数签名。我会抽象掉部分(而非全部)细节。
引擎核心本身由几个子组件组成:
- 模型执行器(Model Executor):驱动模型的前向传播。目前使用的是
UniProcExecutor,它在单个 GPU 上运行一个Worker进程。后续我们将介绍支持多 GPU 的MultiProcExecutor。 - 结构化输出管理器:用于引导式解码(稍后介绍)。
- 调度器(Scheduler):决定哪些请求进入下一个引擎步骤。它包含:
- 策略设置:可以是 FCFS(先来先服务)或 优先级(Priority)。
waiting(等待)和running(运行)队列。- KV 缓存管理器:分页注意力(PagedAttention[3])的心脏。
KV 缓存管理器维护一个 free_block_queue——即可用 KV 缓存块的资源池(通常有数十万个,具体取决于显存大小和块大小)。在 PagedAttention 期间,这些块作为索引结构,将 Token 映射到其计算出的 KV 缓存块。
标准 Transformer 层(非 MLA[4])的块大小(显存占用)计算方式如下:
2 (Key/Value) * block_size (默认=16) * num_kv_heads * head_size * dtype_num_bytes (例如 bf16 为 2)
在模型执行器构造过程中,会创建一个 Worker 对象,并执行三个关键步骤。(之后,使用 MultiProcExecutor 时,这些步骤会在不同 GPU 上的每个 Worker 进程中独立运行。)
- 初始化设备:
- 为 Worker 分配 CUDA 设备(例如 "cuda:0"),检查模型数据类型支持(例如 bf16)。
- 根据请求的
gpu_memory_utilization(例如 0.8 → 总显存的 80%),校验可用现存是否满足需求。 - 设置分布式配置(DP / TP / PP / EP 等)。
- 实例化
model_runner(包含采样器、KV 缓存和前向传播缓冲区,如input_ids,positions等)。 - 实例化
InputBatch对象(包含 CPU 侧的前向传播缓冲区、KV 缓存块表、采样元数据等)。
- 加载模型:
- 实例化模型架构。
- 加载模型权重。
- 调用
model.eval()(进入 PyTorch 推理模式)。 - 可选:对模型调用
torch.compile()。
- 初始化 KV 缓存:
- 获取每层的 KV 缓存规范。以往通常是
FullAttentionSpec(同构 Transformer),但混合模型(如 Jamba 的滑动窗口或 Transformer/SSM 混合架构)会更复杂(参见 Jenga [5])。 - 执行一次试运行(Dummy Run) 或 性能分析(Profiling),获取 GPU 显存快照,计算可用显存能容纳多少个 KV 缓存块。
- 分配、重塑并将 KV 缓存张量绑定到注意力层。
- 准备注意力元数据(例如设置 FlashAttention 后端),供内核在前向传播中使用。
- (除非指定
--enforce-eager)针对每个预热批次大小,执行一次空跑并录制 CUDA Graph。CUDA Graph 将 GPU 工作序列记录为有向无环图(DAG)。在前向传播时,我们直接回放这些预构建的图,从而减少内核启动开销,优化延迟。
- 获取每层的 KV 缓存规范。以往通常是
我在这里抽象掉了许多底层细节,但上述内容是核心部分,后续章节将反复提及。
引擎初始化完毕,让我们进入 generate 函数。
Generate 函数
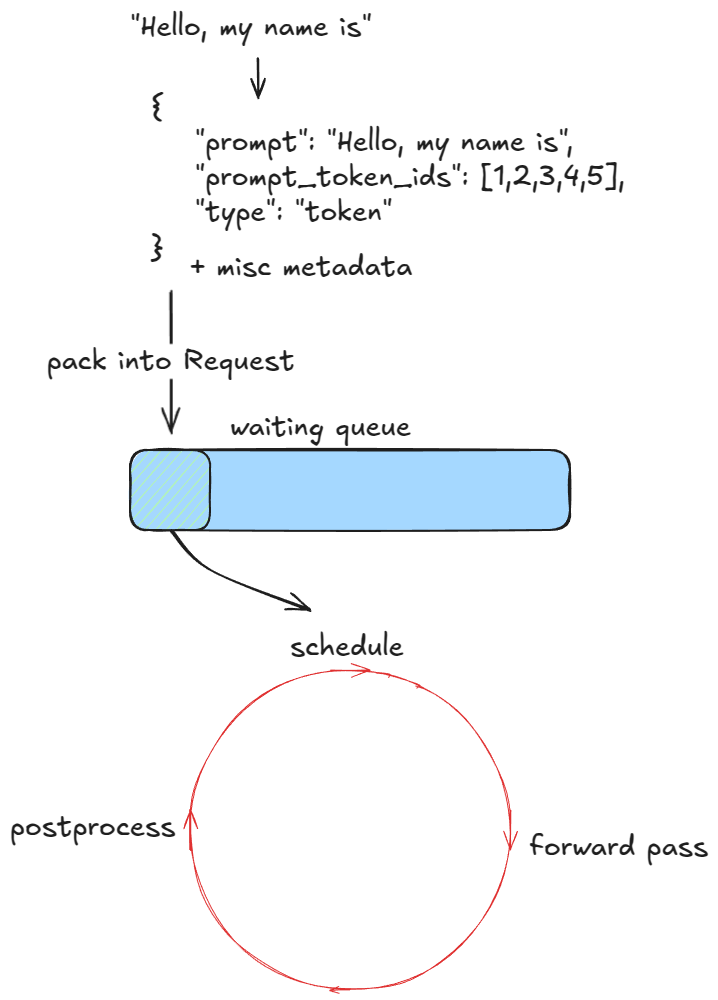
第一步是验证请求并输入引擎。对于每个提示(Prompt):
- 创建唯一请求 ID 并记录到达时间。
- 调用输入预处理器,对提示进行分词,返回包含
prompt,prompt_token_ids,type(文本、Token、嵌入等)的字典。 - 将信息打包进
EngineCoreRequest,添加优先级、采样参数等元数据。 - 传递给引擎核心,核心将其封装为
Request对象,状态设为WAITING,并加入调度器的waiting队列(FCFS 策略为追加,优先级策略为入堆)。
此时,引擎已就绪,执行开始。在同步引擎示例中,这些初始提示是唯一需要处理的请求——运行时无法注入新请求。相比之下,异步引擎支持连续批处理(Continuous Batching[6]):每个步骤结束后,新旧请求会被一并纳入调度考量。
由于前向传播将批次展平为单个序列,且自定义内核可以高效处理,因此即使在同步引擎中,连续批处理在本质上也是受支持的。
只要有请求待处理,引擎就会循环调用 step() 函数。每一步包含三个阶段:
- 调度(Schedule):选择本步骤运行哪些请求(解码 和/或(分块)预填充)。
- 前向传播(Forward pass):运行模型并采样 Token。
- 后处理:将采样到的 Token ID 附加到
Request,反词元化(detokenize),检查停止条件。若请求完成,则清理资源(如将 KV 缓存块归还free_block_queue)并提前返回结果。
- 请求超过其长度限制(
max_model_length或其自身的max_tokens)。 - 采样到的 Token 是 EOS ID(除非启用了
ignore_eos,该选项常用于基准测试,以便强制模型生成指定数量的 Token)。 - 采样到的 Token 匹配采样参数中指定的任何
stop_token_ids。 - 输出内容中检测到停止字符串(Stop strings)——系统会将输出截断至该字符串首次出现的位置,并中止引擎中的请求(请注意:
stop_token_ids会保留在输出结果中,但停止字符串则不会)。”
在流式模式(Streaming mode)下,中间 Token 会在生成时被即时发送,但为了简化讨论,此处暂略过不表。
接下来,我们将深入剖析调度机制。
调度器 (Scheduler)
推理引擎主要处理两种工作负载:
- 预填充(Prefill)请求:对所有提示 Token 进行一次前向传播。这通常是计算密集型(Compute-bound) 的(阈值取决于硬件和提示长度)。最后,我们从最后一个 Token 位置的概率分布中采样一个新 Token。
- 解码(Decode)请求:仅对最近生成的一个 Token 进行前向传播。所有之前的 KV 向量都已缓存。这是访存密集型(Memory-bandwidth-bound) 的,因为为了计算这一个 Token,我们仍需加载所有 LLM 权重(及 KV 缓存)。
在后续的基准测试章节中,我们将利用 Roofline 模型来分析 GPU 性能。这将深入剖析预填充(Prefill)与解码(Decode)性能特征背后的原理。
vLLM V0 版本的调度器仅能串行处理预填充或解码请求;而 V1 版本的调度器通过优化设计,支持在同一引擎步骤中并行处理这两类请求。
调度器会优先照顾解码(Decode)阶段的请求——即那些已经处于 running 队列中的任务。针对每个此类请求,调度器执行以下操作:
- 计算本步需要生成的 Token 数量(由于存在推测式解码和异步调度,这个数字并不总是 1)。
- 调用 KV 缓存管理器的
allocate_slots方法进行显存分配。 - 从 Token 预算(Token budget)中扣除相应的数量。
随后,处理 waiting 队列中的预填充请求:
- 检索已计算块的数量(若禁用前缀缓存则返回 0)。
- 调用 KV 缓存管理器的
allocate_slots函数。 - 将请求从
waiting移至running,状态设为RUNNING。 - 更新 Token 预算。
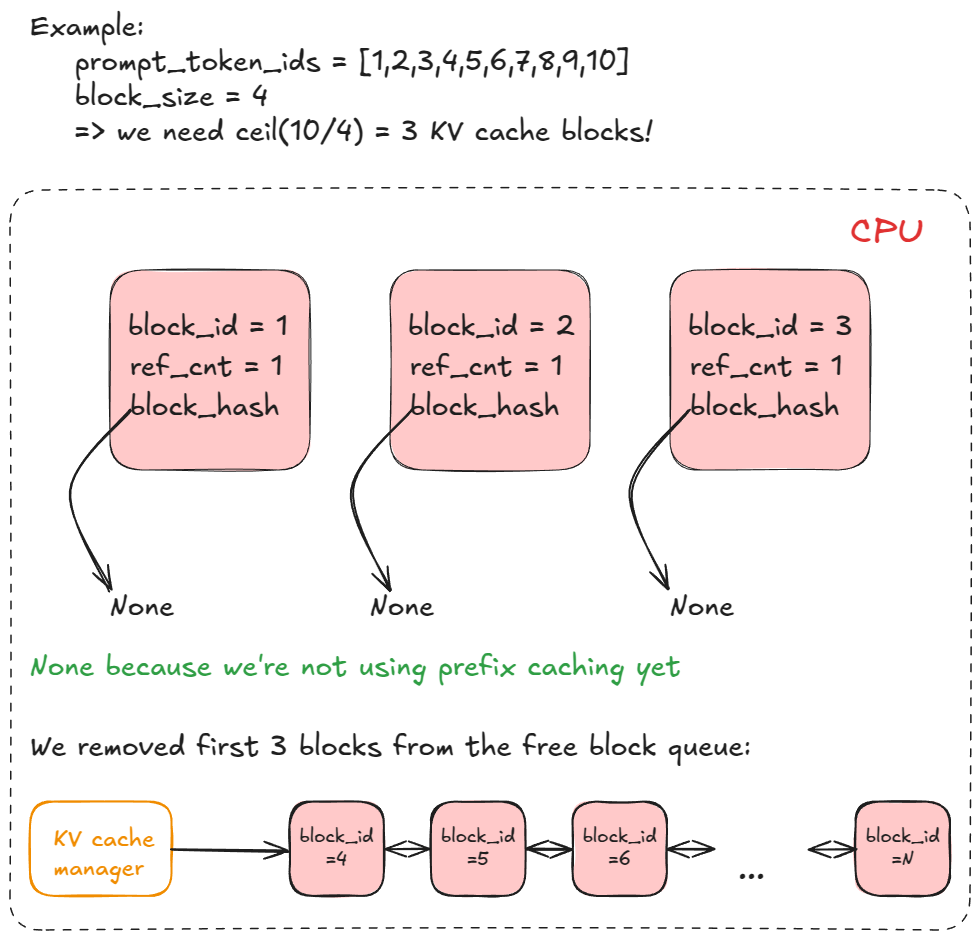
allocate_slots 的具体逻辑:
- 计算块数:确定需分配多少新 KV 缓存块(
n)。默认每块存 16 个 Token。例如,预填充请求有 17 个新 Token,需ceil(17/16) = 2个块。 - 检查可用性:若资源池不足,则提前退出。根据请求类型,引擎可能尝试 重计算抢占(Recompute Preemption) (V0 支持换出抢占),即通过驱逐低优先级请求(调用
kv_cache_manager.free归还块)来腾出空间,或者跳过调度,继续执行现有任务。 - 分配块:通过协调器从
free_block_queue获取前n个块。更新req_to_blocks(请求 ID 到 KV 块列表的映射)。
准备就绪,执行前向传播!
执行前向传播
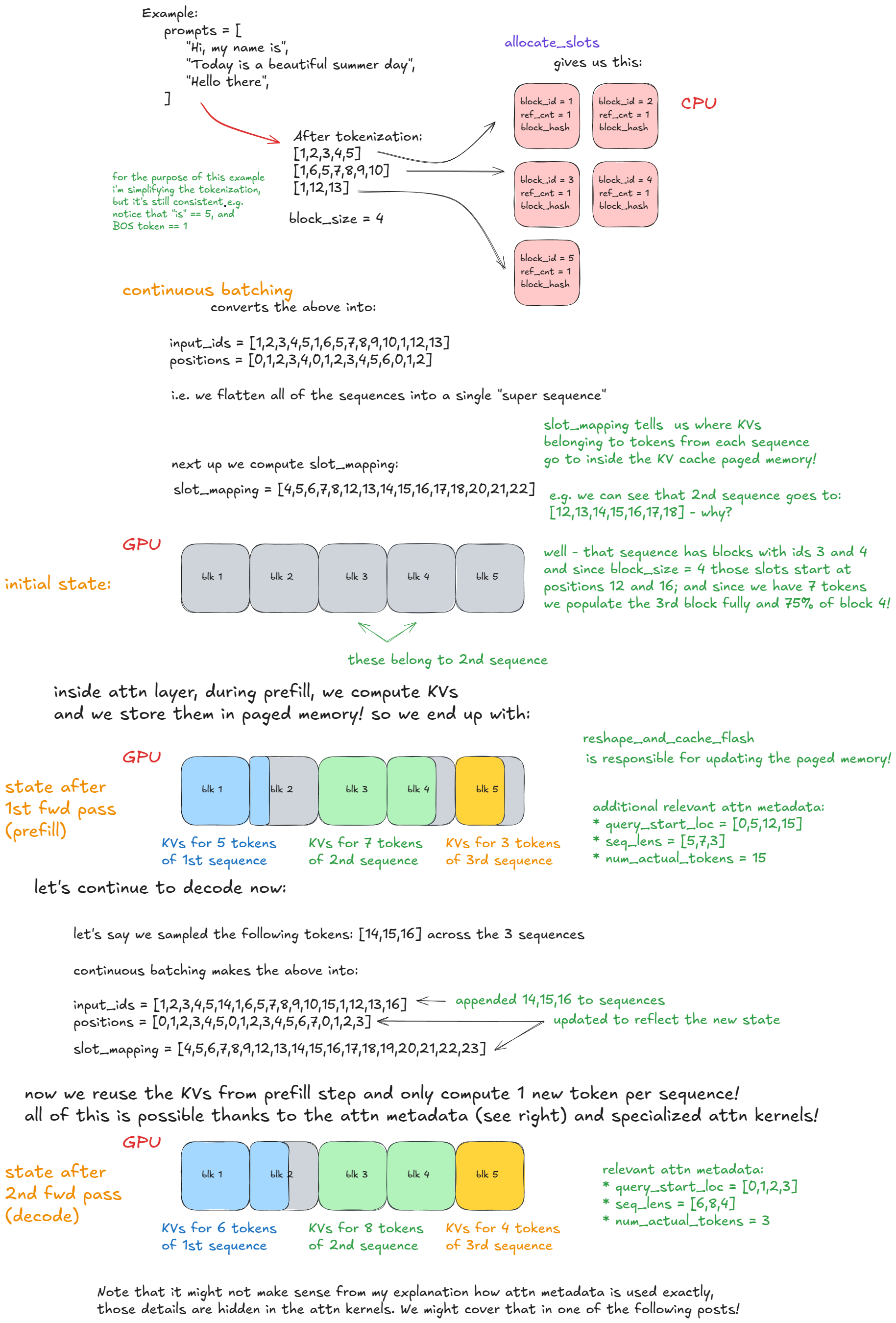
我们调用模型执行器(Model Executor)的 execute_model 方法,它会将任务委托给 Worker,而 Worker 进而委托给模型运行器(Model Runner)。
主要步骤如下:
- 更新状态:从
input_batch剔除已完成请求;更新前向传播元数据(例如:用于索引分页 KV Cache 内存的“每请求 KV Cache 块”信息)。 - 准备输入:将缓冲区从 CPU 复制到 GPU;计算位置信息;构建
slot_mapping(详见后续示例);构建注意力(Attention)元数据。 - 前向传播:使用自定义 PagedAttention 内核运行模型。所有序列被展平并拼接成一个长的超级序列。通过位置索引和注意力掩码确保每个序列只关注属于自身的 Token,这使得连续批处理(Continuous Batching)无需进行右侧填充(Right-padding)。
- 收集最后一个 Token 状态:提取每个序列最终位置的隐藏层状态(Hidden States)并计算 Logits。
- 采样:根据采样配置(贪婪搜索、Temperature、Top-p、Top-k 等)从计算出的 Logits 中采样 Token。
前向传播步骤本身有两种执行模式:
- Eager 模式:当启用 Eager Execution 时,运行标准 PyTorch 前向传播。
- Captured 模式:当未强制执行 Eager 模式时,执行/回放预先录制的 CUDA Graph(还记得我们在引擎构建期间,在初始化 KV Cache 的过程中录制了这些图吗)
下面这个具体的例子应该能清晰地说明连续批处理和分页注意力的工作机制:
高级功能——扩展核心引擎逻辑
随着基础引擎流程的就位,我们现在可以以此为基础研究高级功能。
我们已经讨论了抢占(Preemption)、分页注意力(Paged Attention)和连续批处理(Continuous Batching)。
接下来深入探讨:
- 分块预填充(Chunked Prefill)
- 前缀缓存(Prefix Caching)
- 引导式解码(Guided Decoding,基于 FSM)
- 推测式解码(Speculative Decoding)
- 分离式预填充/解码(Disaggregated P/D)
分块预填充(Chunked Prefill)
分块预填充是一种处理长提示词(Prompt)的技术,它将预填充步骤拆分成更小的块。如果没有这项技术,一个非常长的请求可能会阻塞整个推理步(Step),导致其他预填充请求无法运行。这将推迟所有其他请求的处理,从而增加它们的延迟。
例如,假设每个块包含 n (=8) 个 Token,用小写字母和“-”分隔。一个长提示 P 可能看起来像 x-y-z,其中 z 是一个不完整的块(例如 2 个 Token)。那么执行 P 的完整预填充将需要 ≥ 3 个引擎步(如果它没有在其中一个步骤中被调度执行,则可能 > 3),并且只有在最后一个分块预填充步骤中,我们才会采样产生一个新的 Token。
这是该示例的可视化表示:
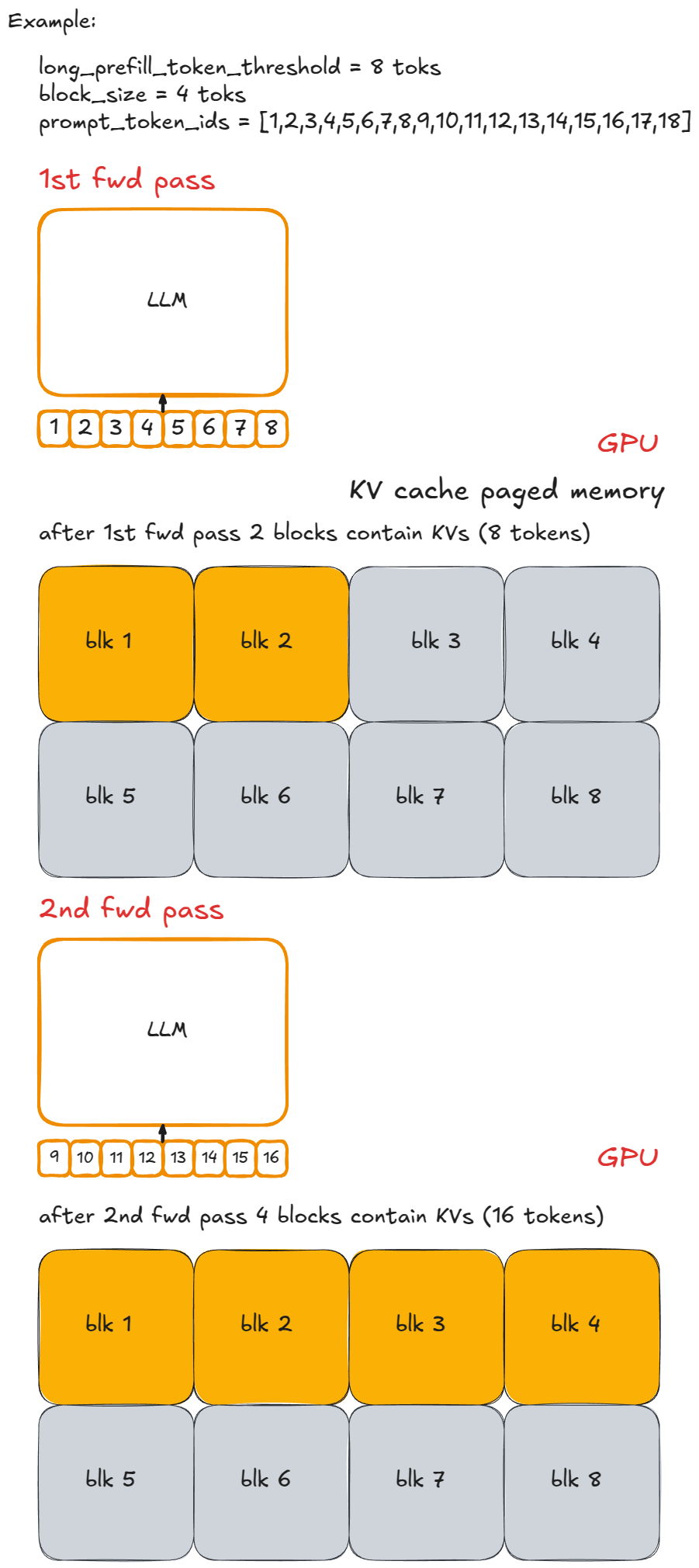
实现逻辑很直观:限制每个步骤处理的新 Token 数量。如果请求的 Token 数超过 long_prefill_token_threshold,则将其截断为该阈值。底层的索引逻辑(如前所述)会负责处理剩下的工作。
在 vLLM V1 中,通过将 long_prefill_token_threshold 设置为正整数来启用分块预填充。(从技术上讲,即使不显式设置,若提示词长度超过 Token 预算,系统也会截断提示词并自动运行分块预填充。)
前缀缓存 (Prefix Caching)
为了解释前缀缓存的工作原理,让我们对原始代码示例进行一些调整:
from vllm import LLM, SamplingParams
long_prefix = "<a piece of text that is encoded into more than block_size tokens>"
prompts = [
"Hello, my name is",
"The president of the United States is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
def main():
llm = LLM(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0")
outputs = llm.generate(long_prefix + prompts[0], sampling_params)
outputs = llm.generate(long_prefix + prompts[1], sampling_params)
if __name__ == "__main__":
main()
前缀缓存(Prefix caching)通过复用多个提示词(Prompts)开头共享的 Token,避免了重复计算——“前缀”之名便由此而来。
关键在于 long_prefix:它指长度超过一个 KV 缓存块(默认 16 个 Token)的任意前缀。为了简化示例,我们假设 long_prefix 的长度恰好是 n x block_size(其中 n ≥ 1)。
换言之,它与块边界严格对齐——否则,由于无法缓存不完整的块,我们将不得不重新计算末尾剩余的
long_prefix_len % block_size个 Token。
如果没有前缀缓存,每次我们处理一个具有相同 long_prefix 的新请求时,都会重新计算所有 n x block_size 个 Token。
有了前缀缓存,这些 Token 只需计算一次(其 KV 值存储在 KV Cache 分页内存中),然后即可被复用,因此系统只需处理新的提示词 Token。这加速了预填充请求(尽管它对解码阶段没有帮助)。
这在 vLLM 中是如何工作的呢?
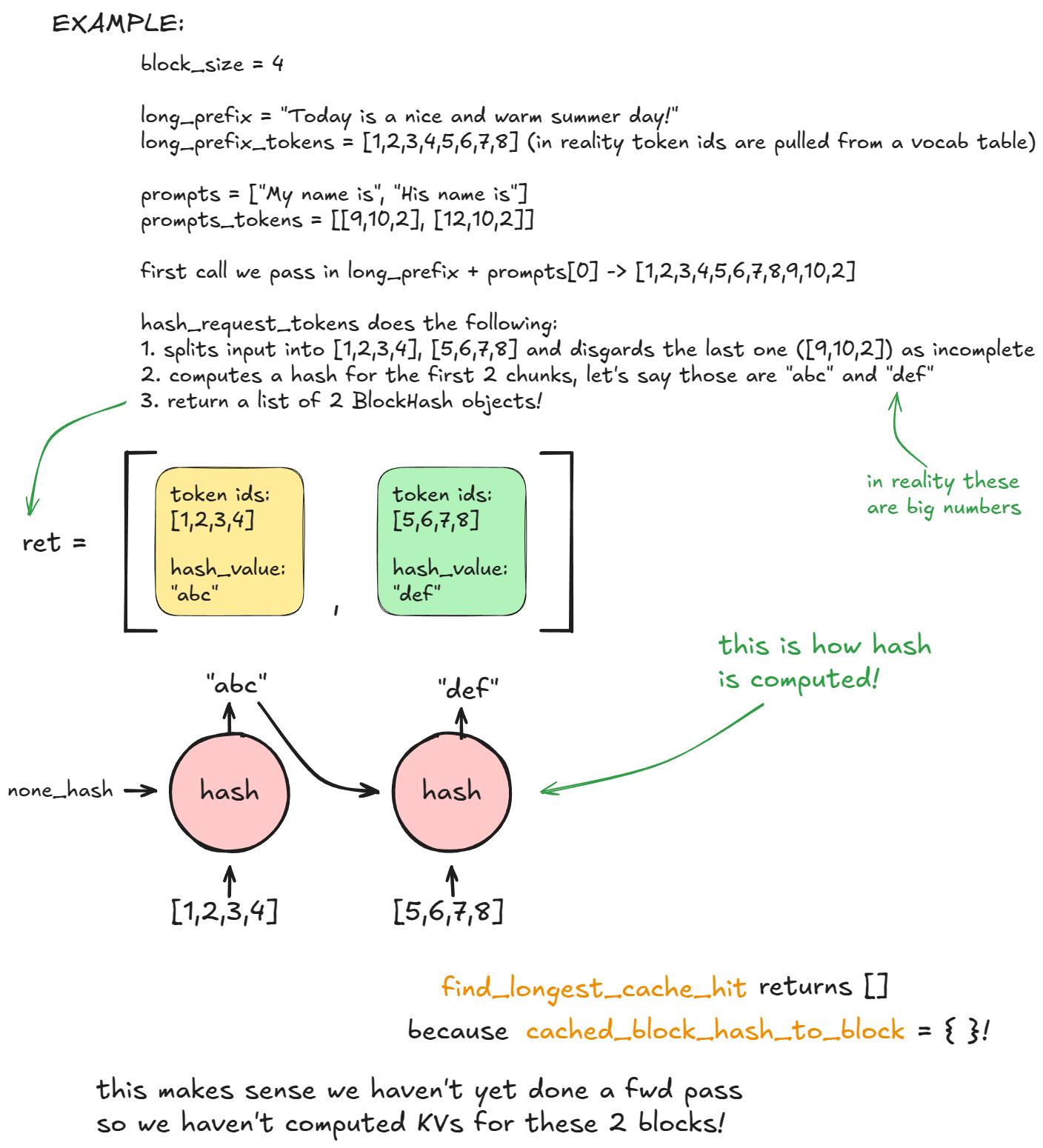
在首次调用 generate 时,位于调度阶段的 kv_cache_manager.get_computed_blocks 方法内部,引擎会调用 hash_request_tokens:
- 此函数将
long_prefix + prompts[0]切分为大小为 16 个 Token 的块。 - 针对每个完整的块,计算其哈希值(可采用内置哈希或 SHA-256,后者速度较慢但哈希冲突更少)。该哈希值的计算融合了前一个块的哈希值、当前块的 Token 以及可选元数据。
可选元数据包括:多模态(MM)哈希、LoRA ID 以及哈希加盐(该值被注入到首个块的哈希中,用于确保只有携带相同 salt 的请求才能复用这些缓存块)。
- 每个结果都存储为一个
BlockHash对象,包含哈希值及其 Token ID。函数返回一个块哈希列表。
该列表存储在 self.req_to_block_hashes[request_id] 中。
接下来,引擎调用 find_longest_cache_hit 检查这些哈希值是否已存在于 cached_block_hash_to_block 中。对于第一个请求,没有找到缓存命中。
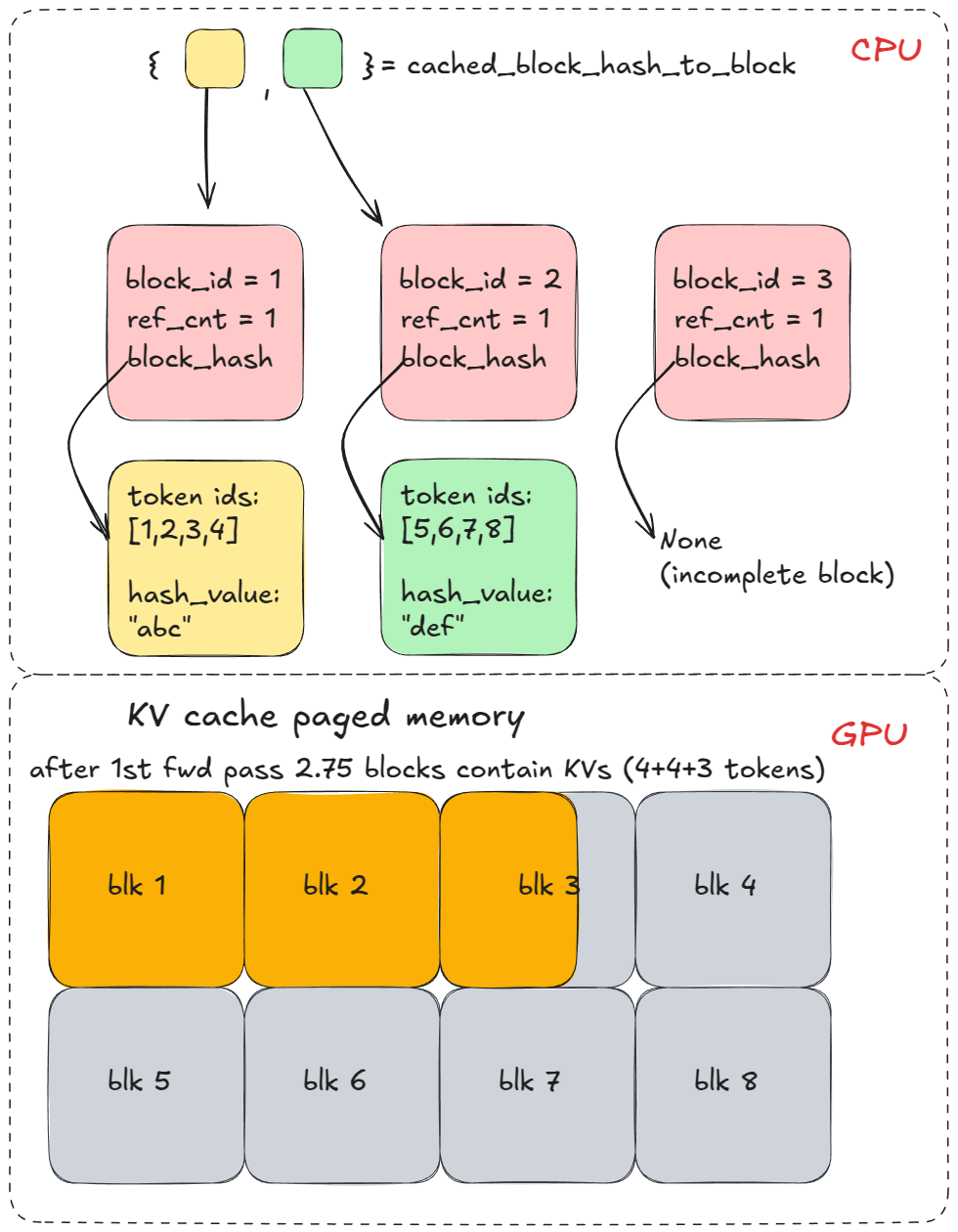
随后调用 allocate_slots,该函数进一步调用 coordinator.cache_blocks,将新的 BlockHash 条目与已分配的 KV 块建立关联,并将其记录在 cached_block_hash_to_block 映射表中。
之后,前向传播过程将在分页 KV 缓存内存中,为上述分配的 KV 缓存块填充对应的 KV 数据。
尽管在随后的许多引擎推理步中,系统会继续分配更多的 KV 缓存块,但这与本示例无关,因为在
long_prefix结束之后,不同请求的生成路径立即发生了分叉(Diverged)。
在第二次使用相同前缀的 generate 调用中,步骤 1-3(计算哈希)会重复,但这次 find_longest_cache_hit 会通过线性查找找到所有 n 个块的匹配项。引擎可以直接复用这些 KV 块。
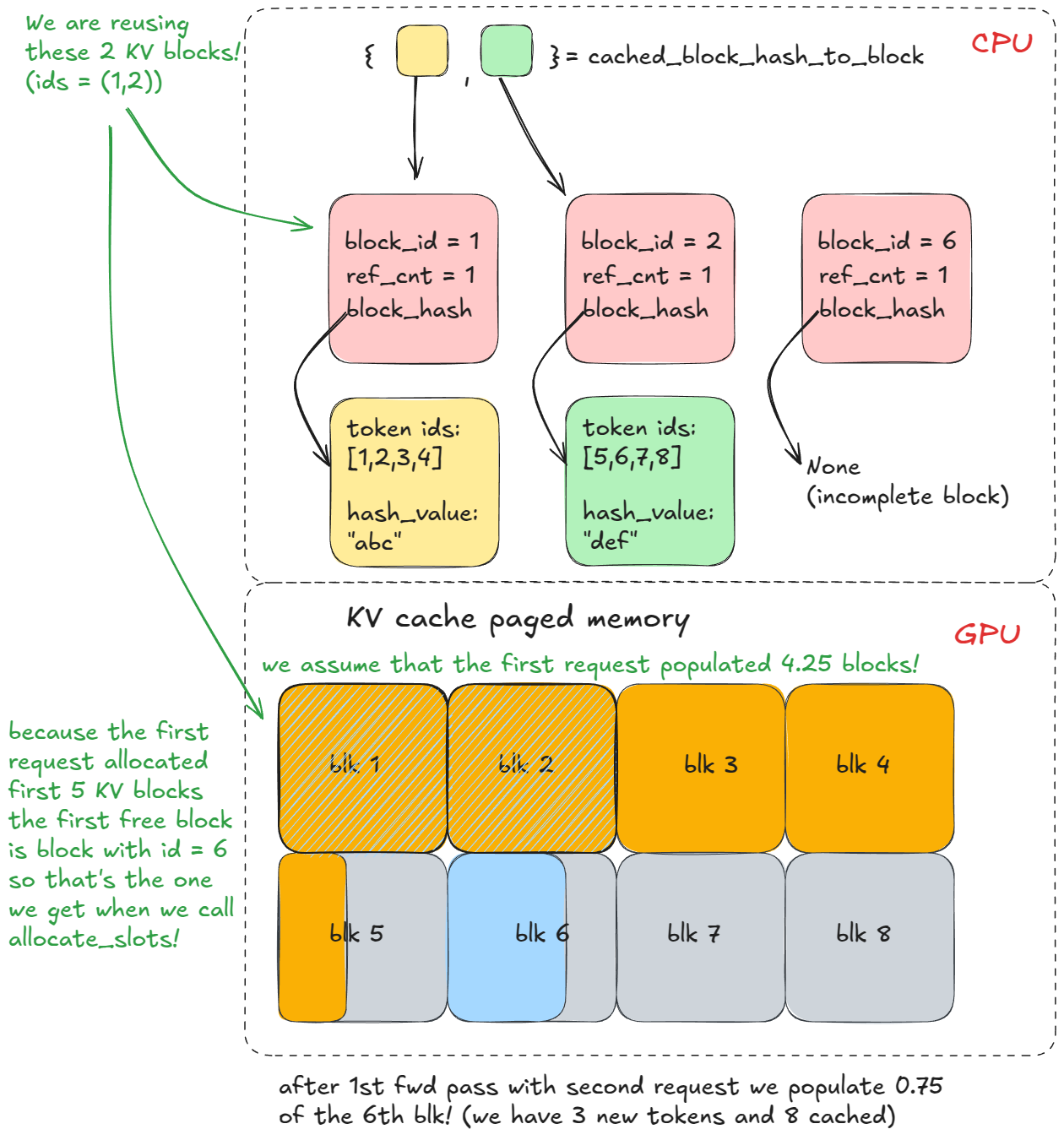
若原始请求仍处于活跃状态,这些块的引用计数将会递增(例如增至 2)。在本例中,首个请求已完成,因此这些块已被释放回资源池,其引用计数重置为 0。但由于我们仍能从 cached_block_hash_to_block 中检索到它们,说明它们依然有效(KV 缓存管理器的逻辑设计保证了这一点),因此我们只需将其从 free_block_queue(空闲块队列)中再次移除。
KV 缓存块只有在即将从 free_block_queue 中被重新分配(从队首弹出)时,若系统检测到该块仍关联有哈希值且存在于 cached_block_hash_to_block 中,才会被判定为失效。此时,我们会清除该块的哈希值,并从 cached_block_hash_to_block 中移除对应条目,从而确保它无法通过前缀缓存被复用(至少无法用于之前的旧前缀)。
这就是前缀缓存的精髓:不要重新计算你已经见过的主要前缀——直接复用它们的 KV Cache 即可!
如果你理解了这个示例,那么你便也掌握了分页注意力(Paged Attention)的工作原理。
前缀缓存默认启用。如需禁用:enable_prefix_caching = False。
引导式解码 (Guided Decoding / FSM)
引导式解码是一种技术,它在每个解码步骤中,通过基于语法(Grammar)的有限状态机(FSM)来约束 Logits。这确保了只有符合语法规则的 Token 才能被采样。
这是一套强大的机制:你可以施加从正则语法(乔姆斯基 3 型,例如任意正则表达式模式)到上下文无关语法(2 型,涵盖大多数编程语言)的各类约束
为了让概念不那么抽象,让我们从最简单的示例开始,基于我们之前的代码:
from vllm import LLM, SamplingParams
from vllm.sampling_params import GuidedDecodingParams
prompts = [
"This sucks",
"The weather is beautiful",
]
guided_decoding_params = GuidedDecodingParams(choice=["Positive", "Negative"])
sampling_params = SamplingParams(guided_decoding=guided_decoding_params)
def main():
llm = LLM(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0")
outputs = llm.generate(prompts, sampling_params)
if __name__ == "__main__":
main()
在我给出的玩具示例中(假设是字符级分词):在预填充阶段,FSM 会屏蔽(Mask)不符合规则的 Logits,使得只有 "P" 或 "N" 是有效候选。如果采样到 "P",FSM 会转移到 "Positive" 分支;下一步只允许 "o",依此类推。
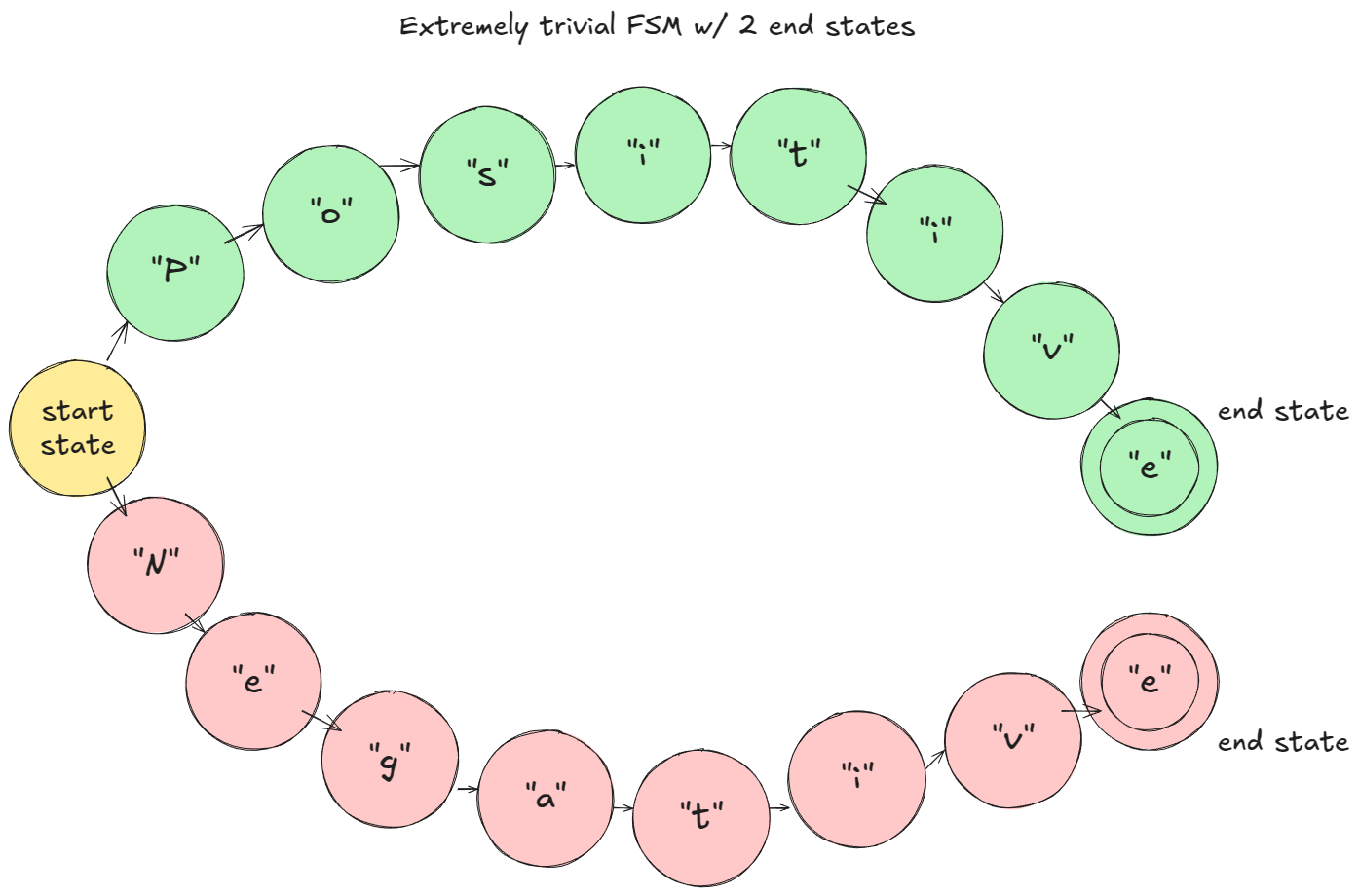
这在 vLLM 中是如何工作的:
- 在构建 LLM 引擎时,会创建一个
StructuredOutputManager;它可以访问分词器(Tokenizer)并维护一个_grammar_bitmask张量。 - 添加请求时,其状态设置为
WAITING_FOR_FSM,并且grammar_init选择后端编译器(例如xgrammar[7];请注意,后端属于第三方代码库)。 - 此请求的文法将被异步编译。
- 在调度期间,如果异步编译已完成,状态将切换到
WAITING,并且request_id将添加到structured_output_request_ids;否则,它将放置在skipped_waiting_requests中,以便在下一个引擎步重试。 - 在调度循环之后(仍在调度阶段内部),如果存在 FSM 请求,
StructuredOutputManager会要求后端准备/更新_grammar_bitmask。 - 在前向传播产生 Logits 后,
xgr_torch_compile的函数会将 Bitmask 扩展到词表大小(扩展倍率 为 32 倍,因为使用 32 位整数存储),并将不允许的 Logits 设为 –∞。 - 采样下一个 Token 后,通过
accept_tokens推进请求的 FSM。直观地看,我们在 FSM 图上移动到了下一个状态。
步骤 6 值得进一步阐释。
若 vocab_size = 32,则 _grammar_bitmask 为单个整数;其二进制形式编码了哪些 Token 是被允许的("1")以及哪些是被禁止的("0")。例如,"101…001" 扩展为长度为 32 的数组 [1, 0, 1, …, 0, 0, 1];对应值为 0 的位置,其 Logits 将被设置为 –∞。对于更大的词表,则会使用多个 32 位整型字(Words),并相应地进行扩展与拼接。后端(例如 xgrammar)负责根据当前的 FSM 状态生成这些位模式。
此处的大部分复杂逻辑都被封装在像 xgrammar 这样的第三方库中。
这里有一个更简单的例子,vocab_size = 8 和 8 位整数(献给喜欢看图的读者):
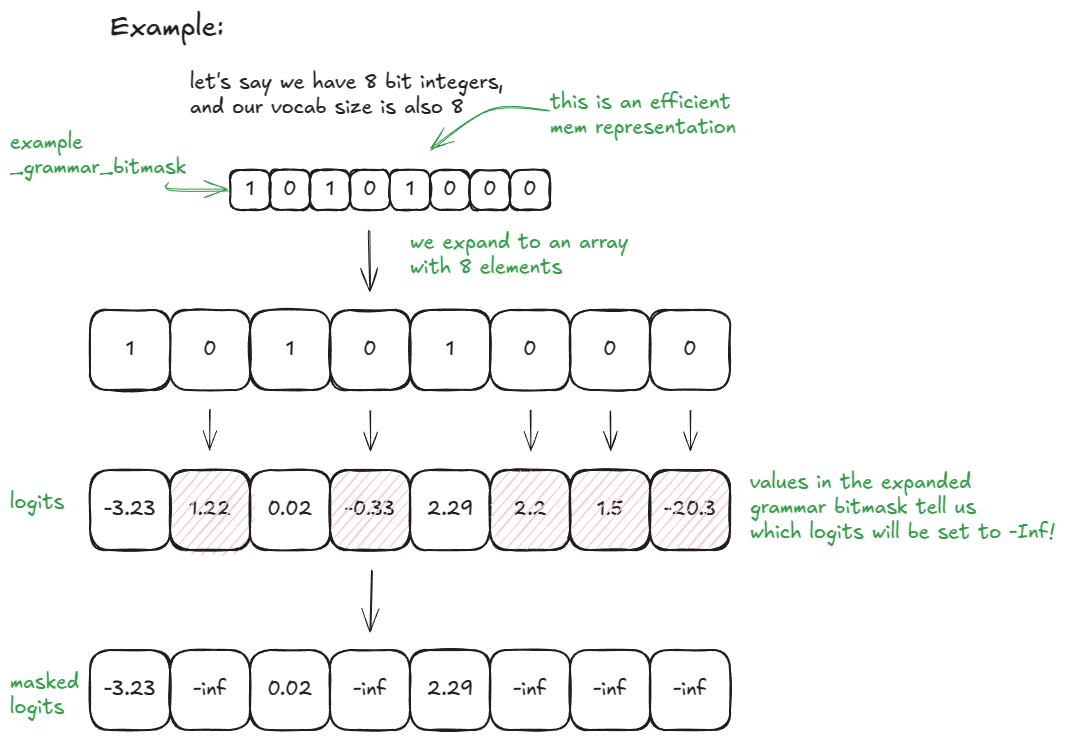
你可以在 vLLM 中通过传入所需的 guided_decoding 配置来启用此功能。
推测式解码 (Speculative Decoding)
在自回归生成中,每个新 Token 都需要大型 LM 进行一次前向传播。这非常昂贵——每一步都要重新加载并运用所有模型权重,只为了计算一个 Token!(假设 Batch Size == 1,通常是 B)
推测式解码[8] 通过引入一个较小的草稿 LM(Draft LM)来加速这一过程。草稿模型以较低的成本“提议” k 个 Token。但我们最终并不希望直接采用小模型的采样结果——它只是用来猜测候选的后续内容。大型模型仍然掌握着有效性的最终决定权。
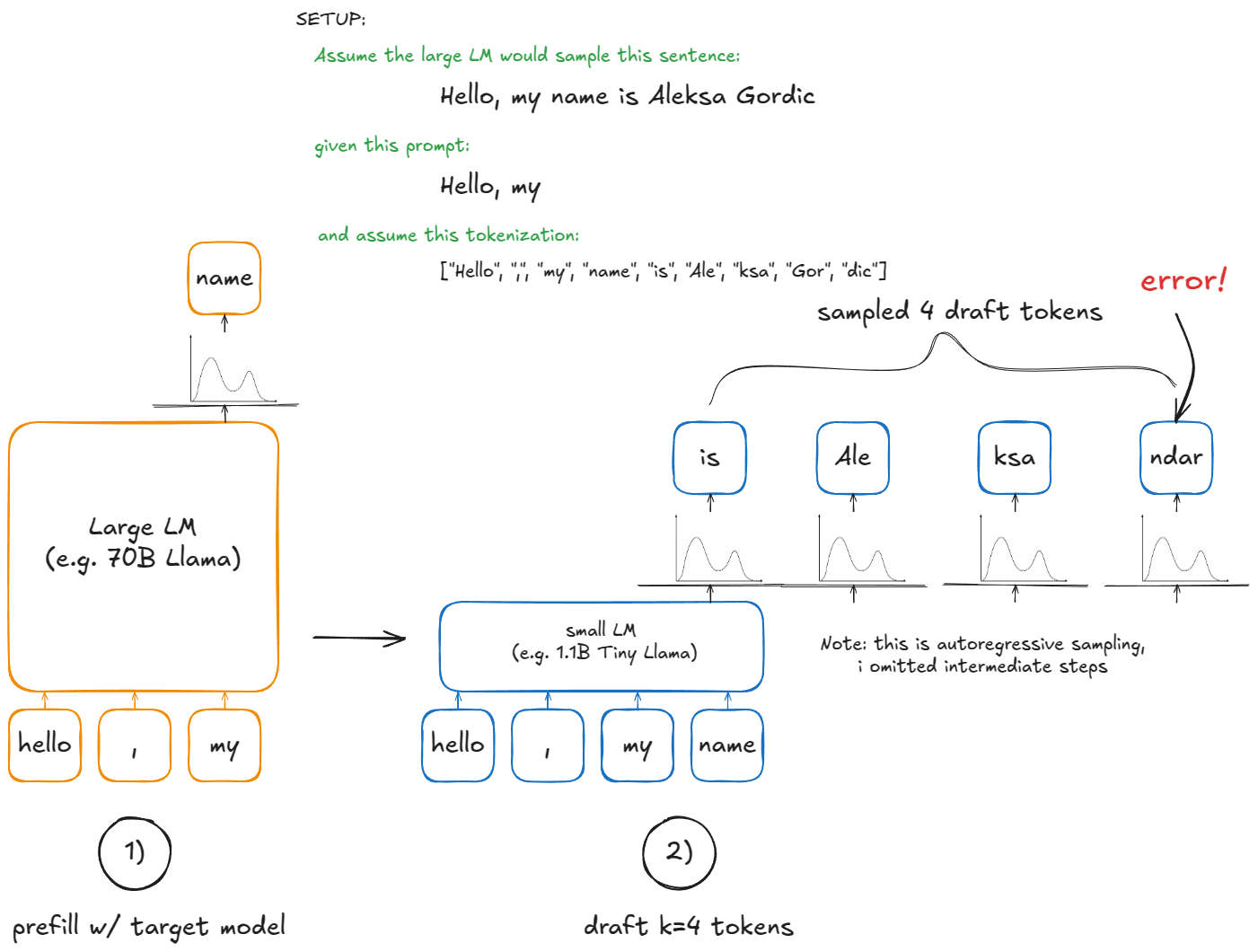
步骤如下:
- 草稿:在当前上下文中运行小模型,并提议
k个 Token。 - 验证:在上下文 +
k个草稿 Token 上运行大模型一次。这将为这k个位置以及一个额外位置生成概率(因此我们得到k+1个候选)。 - 接受/拒绝:从左到右遍历
k个草稿 Token:- 如果大模型对草稿 Token 的概率 ≥ 草稿模型的概率,则接受它。
- 否则,以
p_large(token)/p_draft(token)的概率接受它。 - 在第一次拒绝时停止,或接受所有
k个草稿 Token。 - 如果所有
k个草稿 Token 都被接受,则从大模型中“额外获得”第(k+1)个 Token(因为我们已经计算了该分布,无需额外成本)。- 如果存在拒绝,则在该位置创建一个新的重新平衡分布(
p_large - p_draft,最小值下限截断为 0,归一化为总和为 1),并从中采样最后一个 Token。
- 如果存在拒绝,则在该位置创建一个新的重新平衡分布(
为什么有效:尽管我们利用小模型来提议候选 Token,但接受/拒绝规则保证了在数学期望上,生成的序列分布与我们完全从大模型中逐个采样得到的分布完全一致。这意味着推测式解码在统计上等同于标准自回归解码——但可能快得多,因为一次大模型的前向传递最多可以产出 k+1 个 Token。
vLLM V1 不支持使用完整的 LLM 作为草稿模型,而是实现了更快但精度稍低的提议方案:n-gram、EAGLE[9] 和 Medusa[10]。
一句话介绍每种方案:
- n-gram:截取最后
prompt_lookup_max个 Token;在序列历史中查找先前的匹配项;如果找到,则提议跟随该匹配项的k个 Token;否则缩小窗口并重试,直到prompt_lookup_min。当前实现返回的是第一个匹配项后的
k个 Token。引入近因偏差(Recency bias)并反转搜索方向(即查找最后一个匹配项)似乎更自然? - Eagle:对大型 LM 进行“模型手术”——保留 Embedding 层和 LM Head(语言模型头),用轻量级 MLP 替换 Transformer 层堆栈;将其微调为一个低成本的草稿模型。
- Medusa:在大模型顶层(LM Head 之前的 Embedding 层处)训练辅助的线性头(Linear Heads),以并行预测接下来的
k个 Token;使用这些头比运行单独的小型 LM 更高效。
以下是如何在 vLLM 中使用 ngram 作为草稿方法来调用推测式解码:
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
speculative_config={
"method": "ngram",
"prompt_lookup_max": 5,
"prompt_lookup_min": 3,
"num_speculative_tokens": 3,
}
def main():
llm = LLM(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0", speculative_config=speculative_config)
outputs = llm.generate(prompts, sampling_params)
if __name__ == "__main__":
main()
这在 vLLM 内部是如何工作的?
设置(在引擎构建期间):
- 初始化设备:创建一个
drafter(草稿模型,例如NgramProposer)和一个rejection_sampler(部分逻辑用 Triton 编写)。 - 加载模型:加载草稿模型权重(n-gram 模式下无此操作)。
之后在 generate 函数中(假设我们收到一个全新的请求):
- 使用大模型运行常规预填充步骤。
- 在前向传播和标准采样之后,调用
propose_draft_token_ids(k)从草稿模型中采样k个草稿 Token。 - 将这些存储在
request.spec_token_ids中(更新请求元数据)。 - 在下一个引擎步中,当请求位于运行队列时,将
len(request.spec_token_ids)添加到“新 Token”计数中,以便allocate_slots为前向传播预留足够的 KV 块。 - 将
spec_token_ids复制到input_batch.token_ids_cpu中以形成(上下文 + 草稿)Token 序列。 - 通过
_calc_spec_decode_metadata计算元数据(这会从input_batch.token_ids_cpu复制 Token,准备 Logits 等),然后对草稿 Token 运行大模型前向传播。 - 不再从 Logits 中进行常规采样,而是使用
rejection_sampler从左到右执行接受/拒绝逻辑并生成output_token_ids。 - 重复步骤 2-7,直到满足停止条件。
理解这一点的最佳方法是启动调试器并逐步跟踪代码,但希望本节内容能让你对其有一个初步的认识。参考下图:
P/D 分离(Disaggregated P/D)
我之前已经暗示了预填充/解码分离(Disaggregated P/D)背后的动机。
预填充(Prefill)和解码(Decode)具有截然不同的性能特征——前者是计算密集型(Compute-bound),后者是访存密集型(Memory-bandwidth-bound)。因此,将两者的执行解耦是一种非常合理的设计。。这赋予了我们对延迟更精细的控制力——无论是首字延迟(TTFT)还是字间延迟(ITL)——更多内容请参见基准测试部分。
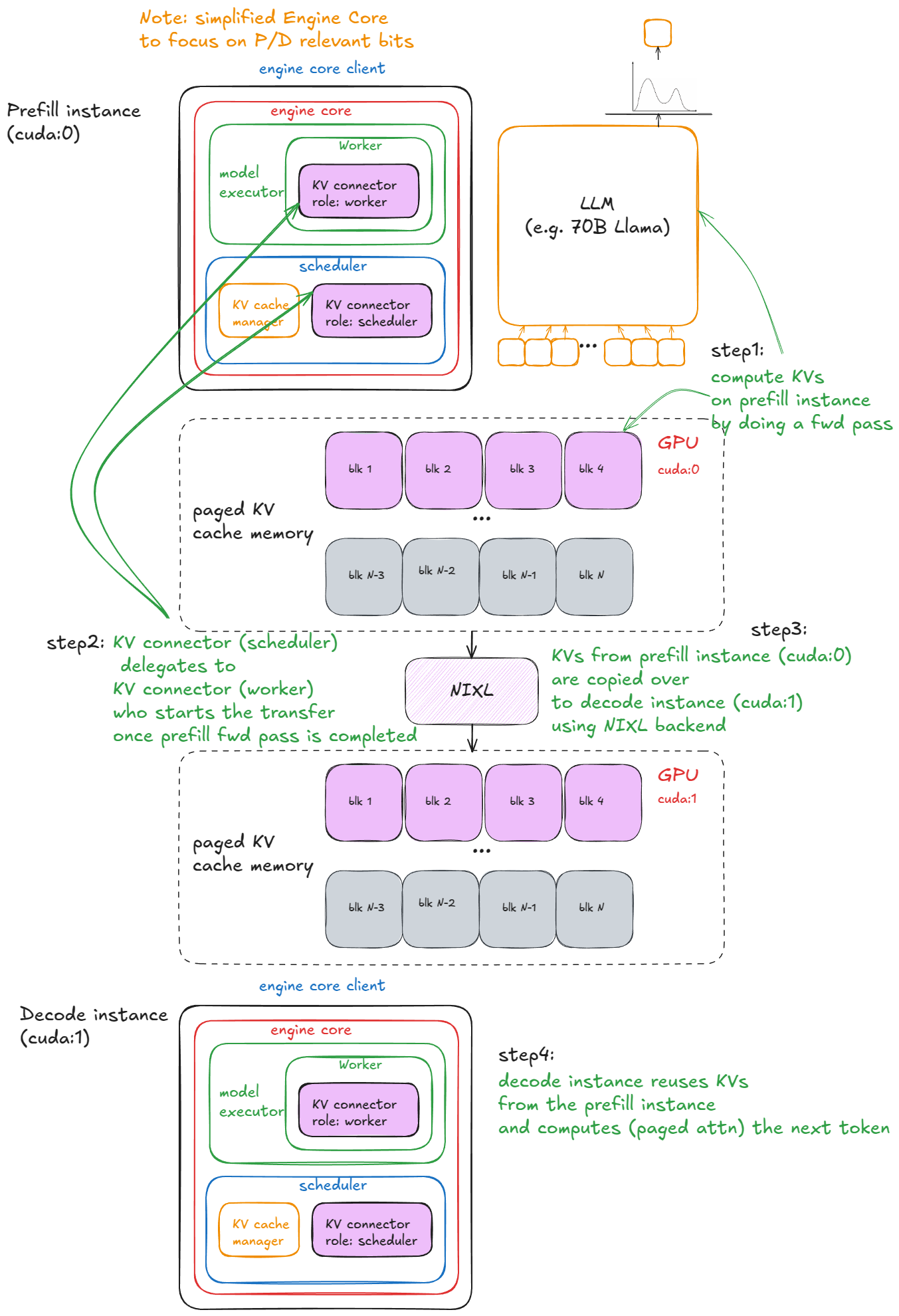
在实践中,我们运行 N 个 vLLM 预填充实例和 M 个 vLLM 解码实例,并根据实时请求的配比进行自动扩缩容(Autoscaling)。预填充 Worker 将 KV 写入专用的 KV Cache 服务;解码 Worker 从中读取。这隔离了长耗时、突发性的预填充任务与稳定的、对延迟敏感的解码任务。
这在 vLLM 中是如何工作的?
为了清晰起见,下面的示例依赖于 SharedStorageConnector,这是一个用于调试的连接器实现,旨在演示其机制。
“连接器(Connector)”是 vLLM 用于处理实例间 KV Cache 交换的抽象层。目前的连接器接口尚未稳定,计划中的近期改进将涉及变更,其中部分变更可能具有破坏性(Breaking changes)。
我们启动 2 个 vLLM 实例(GPU 0 用于预填充,GPU 1 用于解码),然后在这两个实例之间传输 KV Cache:
import os
import time
from multiprocessing import Event, Process
import multiprocessing as mp
from vllm import LLM, SamplingParams
from vllm.config import KVTransferConfig
prompts = [
"Hello, my name is",
"The president of the United States is",
]
def run_prefill(prefill_done):
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
sampling_params = SamplingParams(temperature=0, top_p=0.95, max_tokens=1)
ktc=KVTransferConfig(
kv_connector="SharedStorageConnector",
kv_role="kv_both",
kv_connector_extra_config={"shared_storage_path": "local_storage"},
)
llm = LLM(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0", kv_transfer_config=ktc)
llm.generate(prompts, sampling_params)
prefill_done.set() # notify decode instance that KV cache is ready
# To keep the prefill node running in case the decode node is not done;
# otherwise, the script might exit prematurely, causing incomplete decoding.
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
print("Script stopped by user.")
def run_decode(prefill_done):
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
sampling_params = SamplingParams(temperature=0, top_p=0.95)
ktc=KVTransferConfig(
kv_connector="SharedStorageConnector",
kv_role="kv_both",
kv_connector_extra_config={"shared_storage_path": "local_storage"},
)
llm = LLM(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0", kv_transfer_config=ktc)
prefill_done.wait() # block waiting for KV cache from prefill instance
# Internally it'll first fetch KV cache before starting the decoding loop
outputs = llm.generate(prompts, sampling_params)
if __name__ == "__main__":
prefill_done = Event()
prefill_process = Process(target=run_prefill, args=(prefill_done,))
decode_process = Process(target=run_decode, args=(prefill_done,))
prefill_process.start()
decode_process.start()
decode_process.join()
prefill_process.terminate()
我也尝试过
LMCache[11],这是目前最快的生产级连接器(使用 NVIDIA 的 NIXL 作为后端),但它仍处于实验前沿(Bleeding edge),我在使用过程中遇到了一些 Bug。由于其大部分复杂逻辑位于外部代码库中,因此选择SharedStorageConnector来进行原理解析更为合适。
vLLM 中的步骤如下:
- 实例化:在引擎构造期间,连接器在两个地方被创建:
- 在 Worker 的初始化设备过程中(位于初始化 Worker 分布式环境函数下),角色为 "worker"。
- 在调度器(Scheduler)构造函数中,角色为 "scheduler"。
- 缓存查找:当调度器处理
waiting队列中的预填充请求时(在本地前缀缓存检查之后),它会调用连接器的get_num_new_matched_tokens。这会检查 KV Cache 服务器中是否存在外部缓存的 Token。预填充在此处始终看到 0;解码可能会命中缓存。结果在调用allocate_slots之前被添加到本地计数中。 - 状态更新:调度器随后调用
connector.update_state_after_alloc,记录拥有缓存的请求(预填充无此操作)。 - 元数据构建:在调度结束时,调度器调用
meta = connector.build_connector_meta:- 预填充添加所有
is_store=True的请求(用于上传 KV)。 - 解码添加
is_store=False的请求(用于获取 KV)。
- 预填充添加所有
- 上下文管理器:在前向传播之前,引擎进入 KV 连接器上下文管理器:
- 进入时:调用
kv_connector.start_load_kv。对于解码,这会从外部服务器加载 KV 并将其注入分页内存。对于预填充,这是无操作。 - 退出时:调用
kv_connector.wait_for_save。对于预填充,这会阻塞进程直到 KV 上传到外部服务器。对于解码,这是无操作。
- 进入时:调用
这是一个可视化示例:
从 UniProcExecutor 到 MultiProcExecutor
随着核心技术到位,我们现在可以讨论扩展性问题。
假设您的模型权重无法再装入单个 GPU 的显存中。
首选方案是利用张量并行(例如 TP=8),将模型分片到同一节点上的多个 GPU 上。若模型仍然无法容纳,下一步则是采用跨节点的流水线并行。
- 节点内带宽显著高于节点间带宽,这就是为什么通常首选张量并行 (TP) 而非流水线并行 (PP)。(当然,PP 通信的数据量确实比 TP 少,这也是事实。)
- 我不会涵盖专家并行 (EP),因为我们关注的是标准 Transformer 而非 MoE;我也不会讨论序列并行(Sequence Parallelism),因为 TP 和 PP 是实践中最常用的技术。
在此阶段,我们需要多个 GPU 进程(Worker)和一个编排层来协调它们。这正是 MultiProcExecutor 所提供的。
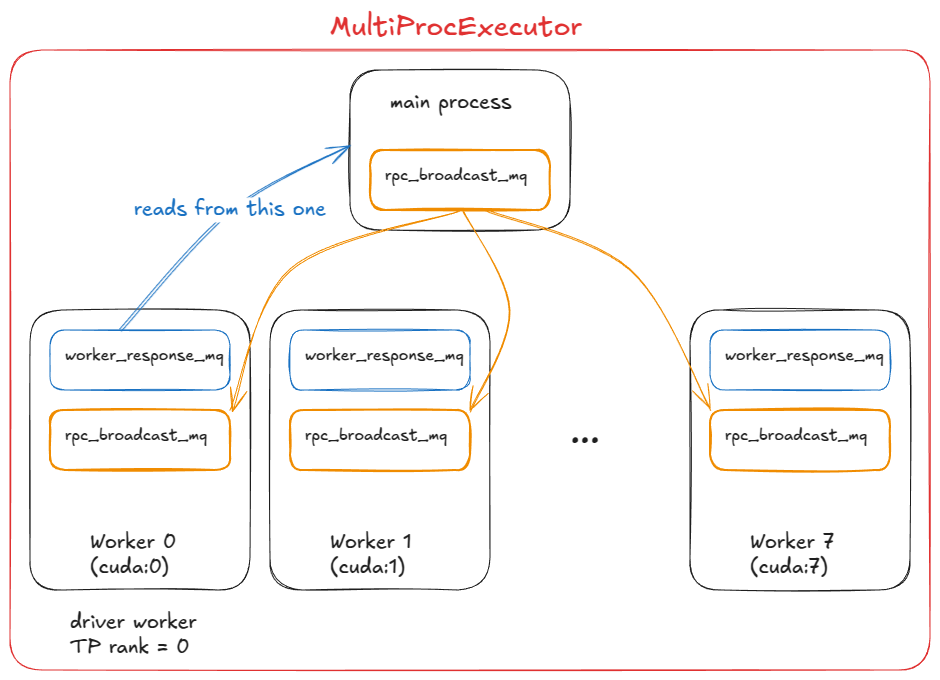
这在 vLLM 中是如何工作的:
MultiProcExecutor初始化一个rpc_broadcast_mq消息队列(底层使用共享内存实现)。- 构造函数遍历
world_size(例如TP=8 ⇒ world_size=8),并通过WorkerProc.make_worker_process为每个 Rank 派生(Spawn)一个守护进程。 - 对于每个 Worker,父进程首先创建读写管道。
- 新进程运行
WorkerProc.worker_main,该函数实例化一个 Worker(经历与UniprocExecutor相同的“初始化设备”、“加载模型”等步骤)。 - 每个 Worker 确定自己是驱动程序(TP 组中的 Rank 0)还是普通 Worker。每个 Worker 设置两个队列:
rpc_broadcast_mq(与父进程共享)用于接收工作。worker_response_mq用于发送响应。
- 在初始化期间,每个子进程通过管道将其
worker_response_mq句柄发送给父进程。一旦所有句柄都收到,父进程解除阻塞——这完成了协调。 - 然后 Worker 进入一个忙循环(Busy Loop),阻塞在
rpc_broadcast_mq.dequeue上。当工作项到达时,它们执行它(就像在UniprocExecutor中一样,但现在是 TP/PP 特定的分区工作)。结果通过worker_response_mq.enqueue发送回去。 - 在运行时,当请求到达时,
MultiProcExecutor将其以非阻塞方式排入rpc_broadcast_mq,供所有子 Worker 使用。然后它等待指定输出 Rank 的worker_response_mq.dequeue来收集最终结果。
从引擎的角度来看,没有任何变化——所有这些多进程复杂性都通过调用模型执行器的 execute_model 被抽象掉了。
- 在
UniProcExecutor的情况下:execute_model直接导致在 Worker 上调用execute_model。 - 在
MultiProcExecutor的情况下:execute_model通过rpc_broadcast_mq间接导致在每个 Worker 上调用execute_model。
至此,我们可以使用相同的引擎接口运行资源允许的任意大小的模型。
下一步是横向扩展(Scale out):启用数据并行(Data Parallelism, DP > 1),在节点之间复制模型,添加轻量级 DP 协调层,在副本之间引入负载均衡,并在前面放置一个或多个 API 服务器来处理传入流量。
分布式系统服务 vLLM
有许多方法可以设置服务基础设施,但为了具体起见,这里有一个示例:假设我们有两个 H100 节点,并希望在它们之间运行四个 vLLM 引擎。
如果模型需要 TP=4,我们可以这样配置节点。
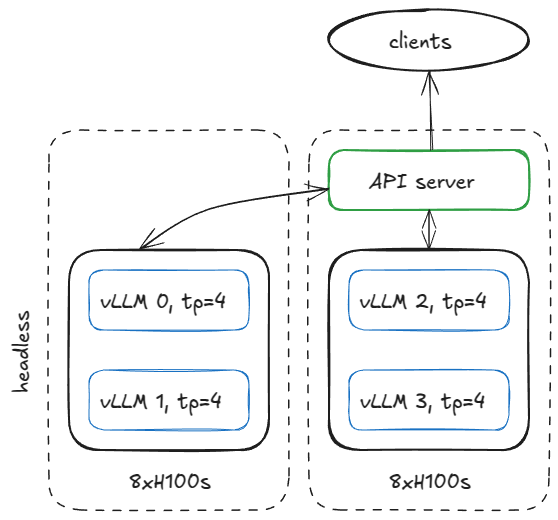
在第一个节点上,以 Headless(无头/纯计算)模式(无 API 服务器)运行引擎,使用以下参数:
vllm serve <model-name>
--tensor-parallel-size 4
--data-parallel-size 4
--data-parallel-size-local 2
--data-parallel-start-rank 0
--data-parallel-address <master-ip>
--data-parallel-rpc-port 13345
--headless
并在另一个节点上运行相同的命令,稍作修改:
- 移除
--headless - 修改 DP 起始 Rank
vllm serve <model-name>
--tensor-parallel-size 4
--data-parallel-size 4
--data-parallel-size-local 2
--data-parallel-start-rank 2
--data-parallel-address <master-ip>
--data-parallel-rpc-port 13345
此处假设网络已完成配置,确保所有节点均能连通指定的 IP 和端口。
这在 VLLM 中是如何运作的?
在 Headless 服务器节点上
在 Headless 节点上,CoreEngineProcManager 启动 2 个进程(每个 --data-parallel-size-local),每个进程运行 EngineCoreProc.run_engine_core。这些函数中的每一个都会创建一个 DPEngineCoreProc(引擎核心),然后进入其忙循环。
DPEngineCoreProc 初始化其父 EngineCoreProc(EngineCore 的子类),它会:
- 创建
input_queue和output_queue(queue.Queue)。 - 使用
DEALERZMQ 套接字(异步消息库)与另一个节点上的前端进行初始握手,并接收协调地址信息。 - 初始化 DP 组(例如使用 NCCL 后端)。
- 使用
MultiProcExecutor(如前所述,在 4 个 GPU 上TP=4)初始化EngineCore。 - 创建一个
ready_event(threading.Event)。 - 启动一个输入守护线程 (
threading.Thread) 运行process_input_sockets(…, ready_event)。类似地启动一个输出线程。 - 在主线程中,等待
ready_event,直到所有 4 个进程(跨 2 个节点)的所有输入线程都完成了协调握手,最终执行ready_event.set()。 - 一旦解除阻塞,它(主线程)会向前端发送一个包含元数据(例如,分页 KV 缓存内存中可用的
num_gpu_blocks)的“就绪”消息。 - 主线程、输入线程和输出线程然后进入各自的忙循环。
总结:我们最终得到 4 个子进程(每个 DP 副本一个),每个进程运行一个主线程、输入线程和输出线程。它们与 DP 协调器和前端完成协调握手,然后每个进程的这三个线程都以稳态的忙循环运行。
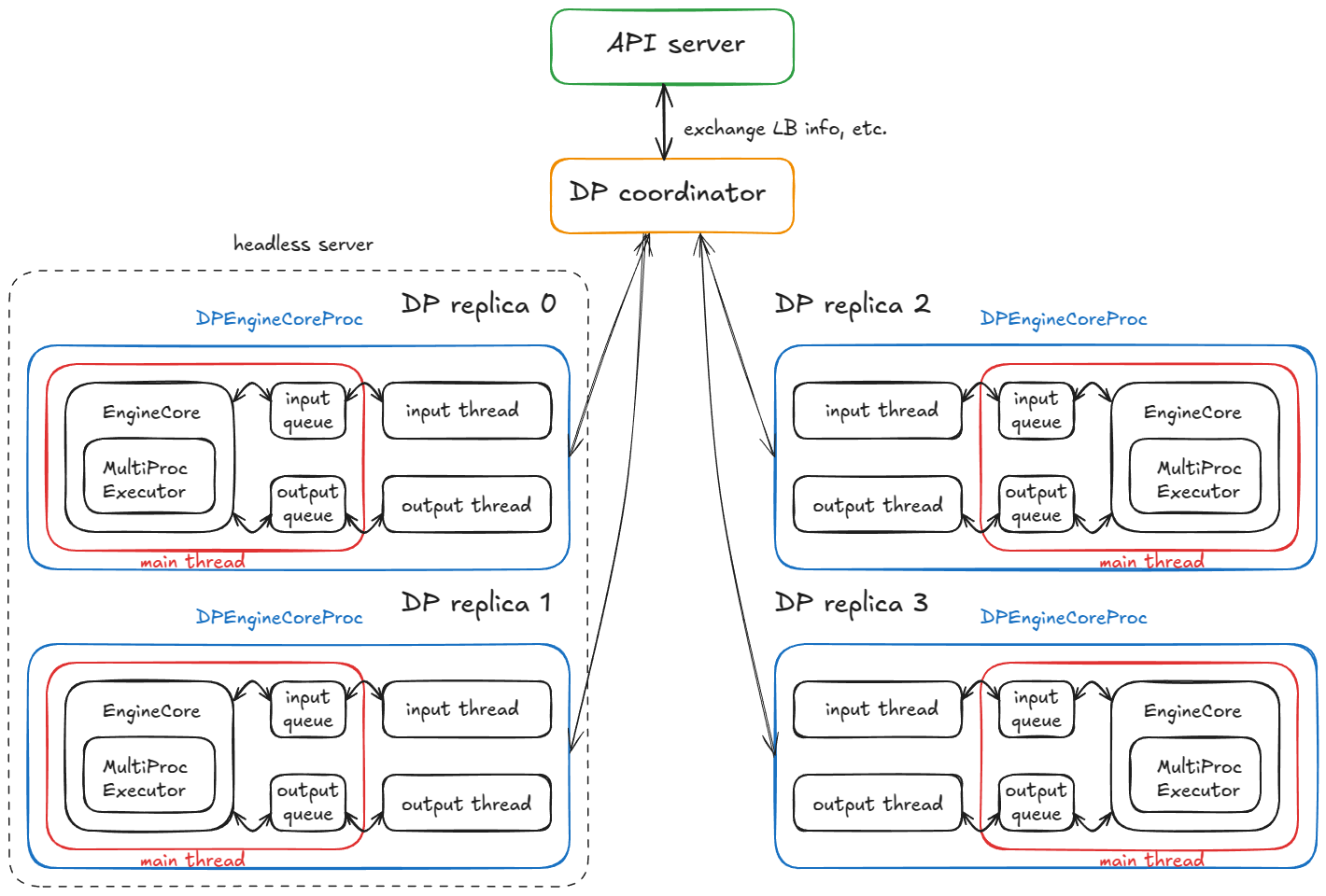
当前稳态:
- 输入线程——阻塞在输入套接字上,直到请求从 API 服务器路由过来;收到后,它解码负载,通过
input_queue.put_nowait(...)将工作项排入队列,然后返回阻塞在套接字上。 - 主线程——在
input_queue.get(...)上唤醒,将请求输入引擎;MultiProcExecutor运行前向传播并将结果排入output_queue。 - 输出线程——在
output_queue.get(...)上唤醒,将结果发送回 API 服务器,然后恢复阻塞。
附加机制:
- DP 波次计数器(DP wave counter)——系统跟踪“波次(Waves)”;当所有引擎都空闲时,它们会进入静默状态(Quiesce);当新工作到达时,计数器会递增(这对于协调/指标很有用)。
- 控制消息——API 服务器不仅可以发送推理请求(例如,中止指令和实用程序/控制 RPC)。
- 用于步调一致(Lockstep)同步的虚拟步进(Dummy steps)——如果任何 DP 副本有工作,所有副本都会执行一个正向步进;没有请求的副本会执行一个虚拟步进,以参与所需的同步点(避免阻塞活动副本)。
强调一下步调一致(Lockstep):这实际上仅在 MoE 模型中是必需的,此时专家层组成了 EP 或 TP 组,而注意力层仍保持 DP 模式。目前该机制在 DP 中总是被执行——这仅仅是因为“内置”的非 MoE DP 用途有限,毕竟你可以直接运行多个独立的 vLLM 实例,并以常规方式在它们之间进行负载均衡。
现在是第二部分,API 服务器节点上发生了什么?
在 API 服务器节点上
我们实例化一个 AsyncLLM 对象(一个围绕 LLM 引擎的 asyncio 封装)。在内部,它创建一个 DPLBAsyncMPClient(数据并行、负载均衡、异步、多进程客户端)。
在 MPClient 的父类内部,launch_core_engines 函数运行并:
- 创建用于启动握手的 ZMQ 地址(如在 Headless 节点上所示)。
- 派生一个
DPCoordinator进程。 - 创建一个
CoreEngineProcManager(与 Headless 节点上的相同)。
在 AsyncMPClient(MPClient 的子类)内部,我们:
- 创建一个
outputs_queue(asyncio.Queue)。 - 我们创建一个 asyncio 任务
process_outputs_socket,它通过输出套接字与所有 4 个DPEngineCoreProc的输出线程通信,并将数据写入outputs_queue。 - 随后,
AsyncLLM的另一个 asyncio 任务output_handler从此队列读取,最终将信息发送到create_completion函数。
在 DPAsyncMPClient 内部,我们创建一个 asyncio 任务 run_engine_stats_update_task,它与 DP 协调器通信。
DP 协调器在前端(API 服务器)和后端(引擎核心)之间进行协调。它:
- 定期向前端的
run_engine_stats_update_task发送负载均衡信息(队列大小、等待/运行中的请求)。 - 通过动态更改引擎数量来处理前端的
SCALE_ELASTIC_EP命令(仅适用于 Ray 后端)。 - 向后端发送
START_DP_WAVE事件(由前端触发时),并报告波次状态更新。
总结一下,前端 (AsyncLLM) 运行着多个 asyncio 任务(请记住:是并发(Concurrent),而非并行(Parallel)):
- 一类任务通过
generate路径处理输入请求(每个新的客户端请求都会生成一个新的 asyncio 任务)。 - 两个任务 (
process_outputs_socket,output_handler) 处理来自底层引擎的输出消息。 - 一个任务 (
run_engine_stats_update_task) 维护与 DP 协调器的通信:发送波次触发器、轮询 LB 状态以及处理动态扩展请求。
最后,主服务器进程创建一个 FastAPI 应用程序,并挂载 OpenAIServingCompletion 和 OpenAIServingChat 等端点,它们暴露 /completion、/chat/completion 和其他接口。然后,该技术栈通过 Uvicorn 提供服务。
所以,综合所有这些,这就是完整的请求生命周期!
你从终端发送:
curl -X POST http://localhost:8000/v1/completions -H "Content-Type: application/json" -d '{
"model": "TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"prompt": "The capital of France is",
"max_tokens": 50,
"temperature": 0.7
}'
接下来会发生什么:
- 请求到达 API 服务器上
OpenAIServingCompletion的create_completion路由。 - 该函数异步地对提示词进行分词,并准备元数据(请求 ID、采样参数、时间戳等)。
- 然后它调用
AsyncLLM.generate,该函数遵循与同步引擎相同的流程,最终调用DPAsyncMPClient.add_request_async。 - 这反过来又调用
get_core_engine_for_request,该函数根据 DP 协调器的状态在引擎之间进行负载均衡(选择分数最小/负载最低的引擎:score = len(waiting) * 4 + len(running))。 ADD请求被发送到所选引擎的input_socket。- 在该引擎上:
- 输入线程——解除阻塞,从输入套接字解码数据,并将工作项放入主线程的
input_queue。 - 主线程——在
input_queue上解除阻塞,将请求添加到引擎,并重复调用engine_core.step(),将中间结果排队到output_queue,直到满足停止条件。注意:
step()会调用调度器、模型执行器(其本身可能是MultiProcExecutor!)等组件。我们在前文中已经见过这个过程了! - 输出线程——在
output_queue上解除阻塞,并通过输出套接字将结果发送回去。
- 输入线程——解除阻塞,从输入套接字解码数据,并将工作项放入主线程的
- 这些结果触发
AsyncLLM输出异步任务(process_outputs_socket和output_handler),它们将 Token 传播回 FastAPI 的create_completion路由。 - FastAPI 附加元数据(完成原因、Logprobs、使用信息等),并通过 Uvicorn 将
JSONResponse返回到你的终端!
至此,一个完整的分布式推理请求生命周期已清晰呈现——这台复杂的分布式机器就被隐藏在一个简单的 curl 命令之后!太有趣了!!!
- 当添加更多 API 服务器时,负载均衡是在操作系统或套接字层面处理的。从应用程序的角度来看,并无显著变化——复杂性已被隐藏。
- 若使用 Ray 作为数据并行 (DP) 后端,你可以暴露一个 URL 端点 (/scale_elastic_ep),以实现引擎副本数量的自动扩缩容。
基准测试与自动调优——延迟 vs 吞吐量
至此,我们已完成对请求处理链路的微观剖析——就像观察“气体分子”在引擎/系统中的流动。现在是时候放大视野,从整体上看待系统,并提出问题:我们如何衡量推理系统的性能?
在最高层次上,有两个此消彼长的指标:
- 延迟(Latency)——从提交请求到返回 Token 的时间。
- 吞吐量(Throughput)——系统每秒可以生成/处理的 Token/请求数量。
延迟对于交互式应用程序(Interactive applications)最重要,因为用户正在等待响应。
吞吐量在离线工作负载中很重要,例如用于训练前/训练后的合成数据生成、数据清洗/处理,以及一般而言——任何类型的离线批处理推理作业。
在解释为什么延迟和吞吐量相互制约之前,让我们定义一些常见的推理指标:
| 指标 | 定义 |
|---|---|
TTFT (Time to First Token,首 Token 时间) |
从请求提交到接收到第一个输出 Token 的时间 |
ITL (Inter-Token Latency,Token 间延迟) |
两个连续 Token 之间的时间(例如,从 Token i-1 到 Token i) |
TPOT (Time Per Output Token,每输出 Token 时间) |
请求中所有输出 Token 的平均 ITL |
Latency / E2E (End-to-End Latency,端到端延迟) |
处理请求的总时间,即 TTFT + 所有 ITL 的总和,或等效地,从提交请求到接收到最后一个输出 Token 的时间 |
Throughput (吞吐量) |
每秒处理的总 Token 数(输入、输出或两者),或每秒处理的请求数 |
Goodput (有效吞吐量) |
满足服务级别目标(SLO)的吞吐量,例如最大 TTFT、TPOT 或端到端延迟。例如,只计算满足这些 SLO 的请求的 Token |
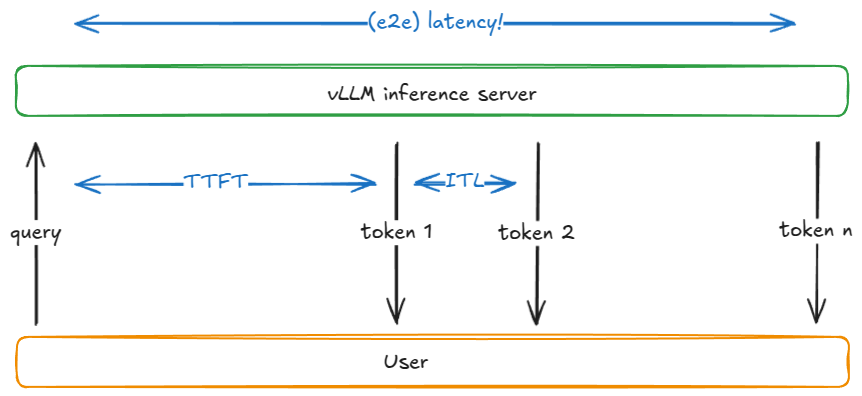
这是一个简化的模型,解释了这两个指标相互制约的性质。
前提:权重 I/O 而非 KV 缓存 I/O 占据主导地位;也就是说,我们处理的是短序列。
当观察 Batch 大小 B 如何影响单个解码步骤时,这种权衡(Tradeoff)变得清晰。随着 B 趋近于 1,ITL 下降:每个步骤的工作量减少,Token 不会与其他 Token“竞争”。随着 B 趋近于无穷大,ITL 上升,因为每个步骤的浮点运算(FLOPs)更多——但吞吐量提高(直到达到峰值性能),因为权重加载的 I/O 开销被分摊到了更多的 Token 上。。
Roofline 模型有助于理解此处:在饱和 Batch 大小(Saturation batch) B_sat 以下,步进时间主要受 HBM 带宽限制(将权重逐层流式传输到片上内存),因此步进延迟几乎是平坦的——计算 1 个与 10 个 Token 可能花费相似的时间。超过 B_sat 后,内核变为计算受限(Compute-bound),步进时间大致随 B 增长;每个额外的 Token 都会增加 ITL。
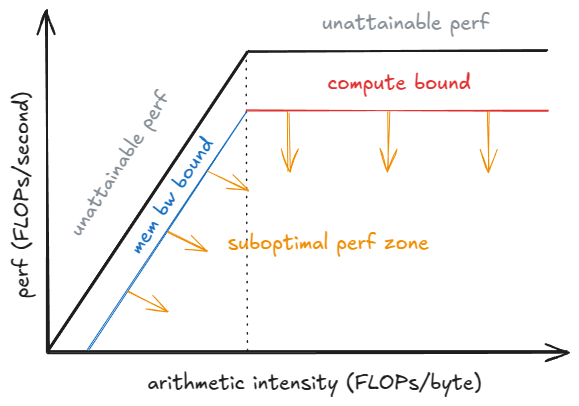
若要进行更严谨的分析,我们必须考虑到内核自动调优的影响:随着 B 的增长,运行时环境可能会切换到针对该形状更高效的内核,从而改变实际达到的性能 P_kernel。步进延迟 t = FLOPs_step / P_kernel,其中 FLOPs_step 是该步进中的计算工作量。由此可见,当 P_kernel 达到峰值性能 P_peak 后,每一步计算量的增加将直接导致延迟的上升。
如何在 vLLM 中进行基准测试
vLLM 提供一个 vllm bench {serve,latency,throughput} 命令行工具,它封装了 vllm/benchmarks/{server,latency,throughput}.py。
这些脚本的作用是:
- latency——使用短输入(默认 32 个 Token)并以小 Batch(默认 8 个)采样 128 个输出 Token。它运行多次迭代并报告 Batch 的端到端延迟。
- throughput——一次性提交一组固定的提示词(默认:1000 个 ShareGPT 样本)(即
QPS=Inf模式),并报告整个运行期间每秒的输入/输出/总 Token 数和请求数。 - serve——启动一个 vLLM 服务器,并通过从泊松(或更一般地,伽马)分布中采样请求到达时间来模拟生产环境的工作负载。它在时间窗口内发送请求,测量我们讨论过的所有指标,并可选择强制执行服务器端最大并发数(通过信号量,例如将服务器限制为 64 个并发请求)。
以下是如何运行延迟脚本的示例:
vllm bench latency
--model <model-name>
--input-tokens 32
--output-tokens 128
--batch-size 8
还有一个自动调优(Auto-tune)脚本,它驱动 serve 基准测试以找到满足目标 SLO(例如,“在 p99 端到端延迟 < 500 毫秒的情况下最大化吞吐量”)的参数设置,并返回建议的配置。
CI 中使用的基准测试配置位于
.buildkite/nightly-benchmarks/tests。
结语
我们从基本的引擎核心(UniprocExecutor)开始,添加了推测式解码和前缀缓存等高级功能,扩展到 MultiProcExecutor(具有 TP/PP > 1),最后实现了横向扩展,将所有功能封装在异步引擎和分布式服务技术栈中,并最终讨论了如何衡量系统性能。
vLLM 还包含我在此跳过的特殊处理。例如:
- 多样化的硬件后端:TPU、AWS Neuron (Trainium/Inferentia) 等。
- 架构/技术:
MLA、MoE、编码器-解码器(例如 Whisper)、池化/嵌入模型、EPLB、m-RoPE、LoRA、ALiBi、无注意力变体、滑动窗口注意力、多模态 LLM 和状态空间模型(例如 Mamba/Mamba-2、Jamba)。 - TP/PP/SP。
- 混合 KV 缓存逻辑(Jenga)、更复杂的采样方法(如束搜索 Beam Search)等等。
- 实验性功能:异步调度。
令人欣慰的是,这些大多数都与上述主要流程正交(Orthogonal)——你几乎可以把它们当作“插件”(当然,实际中存在一些耦合)。
我热爱理解系统。话虽如此,在这个高度下,细节的清晰度确实有所牺牲。在接下来的文章中,我将深入研究特定的子系统,并探讨其细枝末节。
致谢
非常感谢 Hyperstack 在过去一年中为我的实验提供了 H100 GPU!
感谢 Nick Hill (vLLM 核心贡献者, RedHat)、Mark Saroufim (PyTorch)、Kyle Krannen (NVIDIA, Dynamo) 和 Ashish Vaswani 阅读了这篇博客文章的预发布版本并提供了反馈!
"Jenga: Effective Memory Management for Serving LLM with Heterogeneity" ↩︎
"DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model" ↩︎
"Jenga: Effective Memory Management for Serving LLM with Heterogeneity" ↩︎
"Orca: A Distributed Serving System for Transformer-Based Generative Models" ↩︎
"XGrammar: Flexible and Efficient Structured Generation Engine for Large Language Models" ↩︎
"Accelerating Large Language Model Decoding with Speculative Sampling" ↩︎
"EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty" ↩︎
"Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads" ↩︎